How do these "neural network style transfer" tools work?
Hello! Last week I posted about magical machine learning art tools.
This got me to thinking – what would other cool machine learning art tools look like? For example! Sometimes I make drawings, like a drawing of a cat. What if machine learning could automatically transform my drawing into a similar-but-better cat drawing? That would be fun!
I started telling this idea to my partner, and he was like “julia, that sounds like you just read some hacker news headlines about generative neural networks and made this up”. Which was essentially correct!
So I wanted to spend a little bit of time understanding how these machine learning art tools actually work, by understanding the math they’re based on (instead of some vague intuitive idea). I’m going to start with A Neural Algorithm of Artistic Style because it’s a short paper and it’s written in a pretty understandable way.
This paper is the work that powers the system deepart.io. The people who made that website are the authors of the paper. Here’s what they advertise on their homepage:
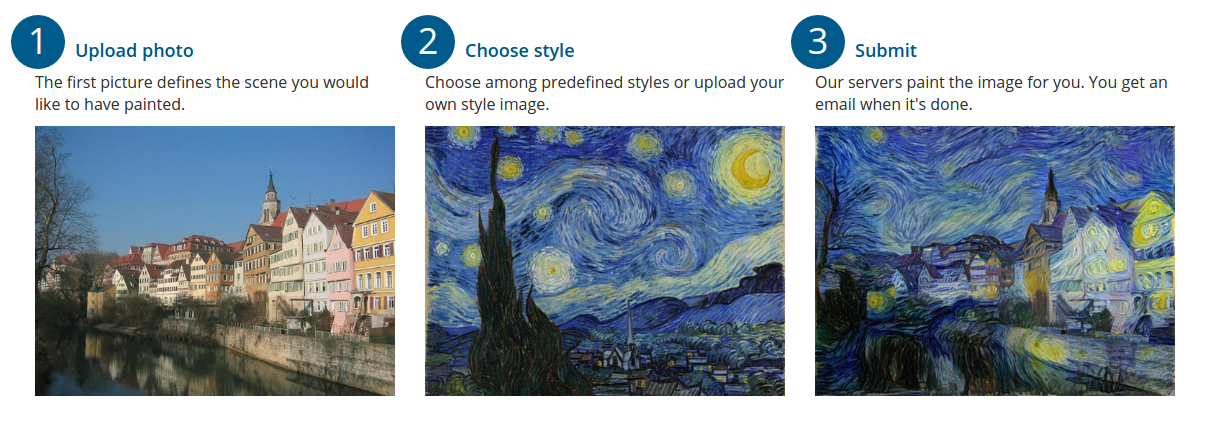
This is pretty different from what I want to do but let’s learn how it works anyway.
“style” and “content”
The core idea of this paper is that you can split an image into “style” (as in, “like the starry night painting”) and “content” (“it’s a picture of some houses on a river”). So, just like you can tell a human painter “paint me my house, but kind in the style of the teletubbies show”, you can tell this algorithm “paint this thing in the style of this other thing”.
This is pretty vague though! Neural networks stuff is all math, so what is the mathematical definition of “style”? That’s what the paper attempts to define, and what we’ll explain a little bit here.
an object recognition network
These neural network art things tend to involve one specific neural network. The neural network used in this “style transfer” tool is the one described in this paper, by the VGG group at Oxford.
The purpose of this network was not to generate art stuff at all! This network’s job is to do image recognition (“that’s a cat! that’s a house!”).
This particular network won the ImageNet 2014 challenge (the challenge that all neural networks image recognition groups seem to participate in) in the “localization” category.
Localization means that you need to recognize an object in the image and say where the object in the image is. So you have to not just know that there is a house, but also to give a box where the house is.
We need a definition of “style” and “content”, and what this network does is to give us a definition for both style and content. How?
a mathematical definition of “content” and “style”
You can see the layers of the neural network here.
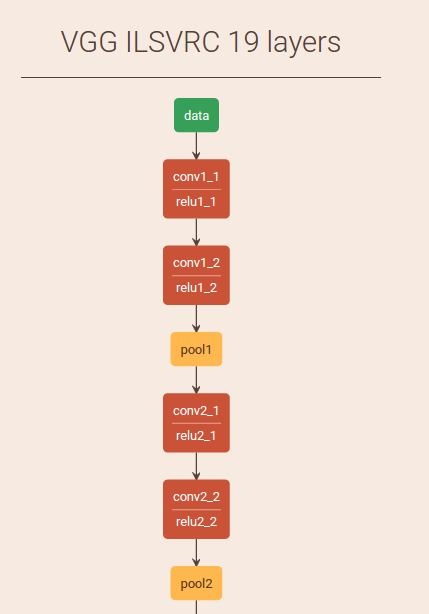
When we put an image into the network, it starts out as a vector of numbers (the red/green/blue values for each pixel). At each layer of the network we get another intermediate vector of numbers. There’s no inherent meaning to any of these vectors.
But! If we want to, we could pick one of those vectors arbitrarily and declare “You know, I think that vector represents the content” of the image.
The basic idea is that the further down you get in the network (and the closer towards classifying objects in the network as a “cat” or “house” or whatever"), the more the vector represents the image’s “content”.
In this paper, they designate the “conv4_2” later as the “content” layer. This seems to be pretty arbitrary – it’s just a layer that’s pretty far down the network.
Defining “style” is a bit more complicated. If I understand correctly, the definition “style” is actually the major innovation of this paper – they don’t just pick a layer and say “this is the style layer”. Instead, they take all the “feature maps” at a layer (basically there are actually a whole bunch of vectors at the layer, one for each “feature”), and define the “Gram matrix” of all the pairwise inner products between those vectors. This Gram matrix is the style.
I still don’t completely understand this inner product thing. Someone tried to explain this to me on twitter a bit but I still don’t really get it. I think it’s explained a bit more in this paper: Texture Synthesis Using Convolutional Neural Networks.
They try different possible style layers:
conv1_1, conv2_1, conv3_1, and conv4_1 in the paper, which all
give different results.
So! Let’s say that we define the Gram matrix at conv3_1 to be the “style”
and the vector at conv4_2 to be the “content” of an image.
Drawing your house in the style of a painting
So. Now we’ve defined “content” and “style”.
Let’s say I have a picture of some houses on a river, and a famous
starry night painting. This picture has a “content” (which is the vector
that you get at layer conv4_2 of the neural network).
The famous painting has a “style”, which is the vector I get by feeding
it into the neural network and taking the Gram matrix at layer conv3_1.
So! What if I could find a picture which has the same “content” as the photo of my house and the same “style” as the famous painting? This is exactly what the paper does.
We start out with some white noise, and define a loss function (“how different is the style from the painting, and how different is the content from the photo?”). This is equation 7 in the paper.
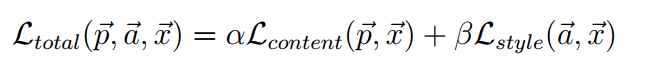
Then we use gradient descent to move our white noise until we get a result that minimizes this loss function. My impression is that gradient descent is pretty fast, so we pretty quickly get the photo of our house painted like a famous painting.
maybe your weird intuitions are right
The exciting thing to me about this is – this is a weird thing that I would not have thought would work. So maybe some of my other weird ideas about neural networks and art would also work, if I tried them out, as long as I find a reasonable mathematical way to formulate them! I do not really have time to do neural networks experiments but maybe I will find some. The Unreasonable Effectiveness of Recurrent Neural Networks is a great read here.
It doesn’t seem trivial at all to figure out what weird art things will work, though – they had to do a surprising-to-me mathematical operation to define the style/texture of a painting (this weird Gram matrix thing where you take all these inner products).
If you want to know more about the exact mathematical details you should read the paper! I found it kinda readable, though I still don’t really understand how they thought of the style definition. (though this depends if you consider partial derivatives readable or not :)). I’ve probably gotten something wrong in here because I’m still pretty new to neural networks but I think this is about right. Let me know if I’ve said something wrong!