TIL: clock skew exists
I learned some new things yesterday about distributed systems yesterday! Redis is a key-value store that can be distributed, and apparently it has a proposal for a locking system called Redlock.
Yesterday I read the articles where Martin Kleppman criticizes Redlock and Redlock’s author, antirez, responds.
These are very interesting to read as a distributed systems n00b – the authors of the articles are making significantly different arguments, and so it’s a useful exercise to try to reason through the arguments and figure out who you think is right.
Martin Kleppman, as far as I understand, argues that Redlock isn’t safe to use because
- processes can pause for arbitrary amount of time (because of garbage collection or CPU scheduling)
- network requests can be arbitrarily delayed at any time
- The clock on a computer can be unreliable (because it goes at the wrong speed, or has jumped back in time)
Probably other reasons too, but those are the ones I understood.
Here’s a chart from his post illustrating how things can go wrong:
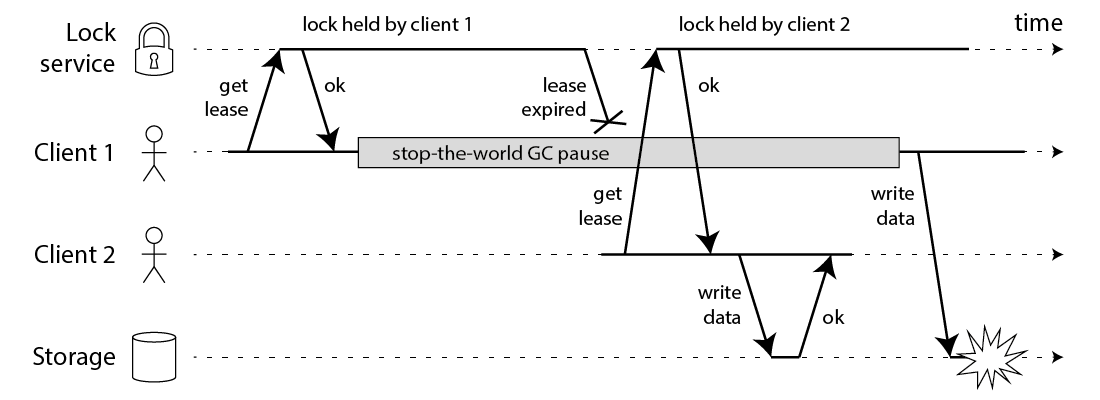
process pauses & network delays are totally real. but, clock skew?
Part of antirez’s response is “well, you can assume your clock is mostly correct though!”.
What they need to do is just, for example, to be able to count 5 seconds with a maximum of 10% error. So one counts actual 4.5 seconds, another 5.5 seconds, and we are fine.
Now, I totally believe in garbage collection. I’ve seen services become unresponsive because they were garbage collecting. So I definitely believe in process pauses.
I also believe in arbitrary network delays! If you told me that some of my replies saying “hey I’m finished with the lock” would be (very very occasionally) delayed for 1-2 seconds, I’d believe you. 1-2 seconds is a lot of computer time!!
As far as I can tell, either of those two things by themselves is enough to make Redlock not safe. (if you account for process pauses, you could still have another process pause after you account for them, right?)
But, we were talking about clock skew.
Clock skew is when your clock is going, say, 10% or 2x faster than it should. If uncorrected, this is a disaster for a system that depends on knowing the right time.
Here’s the thing – I haven’t seen a lot of systems, but I’ve never seen a system with a clock running too fast. My laptop’s clock mostly works, as far as I know my servers at work have approximately correct clocks (though maybe they don’t and I just don’t know!). Why is Martin Kleppman so worried about this?
I asked about this, and @handler and @aphyr both helped me out. They were basically both totally “julia systems with clocks that go at bogus speeds totally exist. 2x clock skew is real”.
a few links about clock skew
Check out this 1999 paper by Nelson Minar that surveys NTP (network time protocol) servers and finds that they’re often serving incorrect times.
The trouble with timestamps by @aphyr has a great explanation about why you should care about your clock.
Here’s an attack on Tor where if you induce high CPU load on a node, the temperature is likely to cause the clock skew to increase on that node. There’s also a follow up paper
Leap seconds are real. (there was one in 2015!) This post 5 different ways to handle leap seconds has a ton of cool graphs. (thanks Nick Coghlan!)
Google pretty much knows what time it is – they invested a ton of time in a system called Spanner. Here are a couple of articles about that.
distributed systems & weird computer things
Distributed systems researchers are really really concerned with adverse, sometimes uncommon, things that can happen to your computer (like clock skew).
I think they’re concerned for three reasons:
- they’re trying to prove theorems, and if you’re proving a theorem you need to worry about all the edge cases
- they’re operating literally 20 million computers. if you have 20 million computers everything that can go wrong with a computer will go wrong.
- some of those seemingly uncommon things are actually quite common (like network partitions)
I don’t know at all how many computers Google has, but I bet it’s a lot. Like 20 million or something.
Reasons 1 and 2 are related – if you prove a theorem that your system is safe, then it’ll be safe even if you have 20 million computers. Theorems are the best.
So my laptop’s clock is probably mostly okay, but at Google scale I’d imagine you have computers with broken clocks all the time.
reasoning about distributed systems is interesting
I’m not a distributed systems engineer, really. (though I deal with some at work sometimes). I think, if you have plans to interact with distributed systems in the future, it’s really useful to try to reason through issues like this for yourself! There’s a ton of terminology (the first time I watched one of the Jepsen talks I was like “wat.”)
So I think it’s fun to practice sometimes. Maybe one day you learn what linearizability is! and 6 months later you’re like “oh I actually didn’t get it I was totally wrong.”
clock skew is real
People I know have experienced it! It is not just a weird theoretical thing to give researchers jobs. Huh.
thanks for Camille Fournier, Michael Handler, and Kyle Kingsbury for trying to explain distributed systems things to me. I have likely made lots of mistakes in writing this, and those mistakes are all mine :)