New talk: Making Hard Things Easy
A few weeks ago I gave a keynote at Strange Loop called Making Hard Things Easy. It’s about why I think some things are hard to learn and ideas for how we can make them easier.
Here’s the video, as well as the slides and a transcript of (roughly) what I said in the talk.
the video
the transcript

Hello, Strange Loop! Strange Loop is one of the first places I spoke almost 10 years ago and I’m so honored to be back here today for the last one. Can we have one more round of applause for the organizers?

I often give talks about things that I'm excited about, or that I think are really fun.
But today, I want to talk about something that I'm a little bit mad about, which is that sometimes things that seem like they should be basic take me 10 years or 20 years to learn, way longer than it seems like they should.
One thing that took me a long time to learn was DNS, which is this question of – what’s the IP address for a domain name like example.com? This feels like it should be a straightforward thing.

But seven years into learning DNS, I’d be setting up a website. And I’d feel like things should be working. I thought I understood DNS. But then I’d run into problems, like my domain name wouldn’t work. And I’d wonder – why not? What’s happening?

And sometimes this would feel kind of personal! This shouldn't be so hard for me! I should understand this already. It's been seven years!
And this "it's just me" attitude is often encouraged -- when I write about finding things hard to learn on the Internet, Internet strangers will sometimes tell me: "yeah, this is easy! You should get it already! Maybe you're just not very smart!"
But luckily I have a pretty big ego so I don't take the internet strangers too seriously. And I have a lot of patience so I'm willing to keep coming back to a topic I'm confused about. There were maybe four different things that were going wrong with DNS in my life and eventually I figured them all out.
So, hooray! I understood DNS! I win! But then I see some of my friends struggling with the exact same things.
They're wondering, hey, my DNS isn't working. Why not?

And it doesn't end. We're still having the same problems over and over and over again. And it's frustrating! It feels redundant! It makes me mad. Especially when friends take it personally, and they feel like "hey I should really understand this already".
Because everyone is going through this. From the sounds of recognition I hear, I think a lot of you have been through some of these same problems with DNS.

I got so mad about this that I decided to make it my job.

I started a little publishing company called Wizard Zines where --
(applause)
Wow. Where I write about some of these topics and try to demystify them.

We're going to talk about bash, HTTP, SQL, and DNS.

For each of them, we're going to talk a little bit about:
a. what's so hard about it?
b. what are some things we can do to make it a little bit easier for each other?




To understand why it’s weird, let’s do a little small demo of bash.
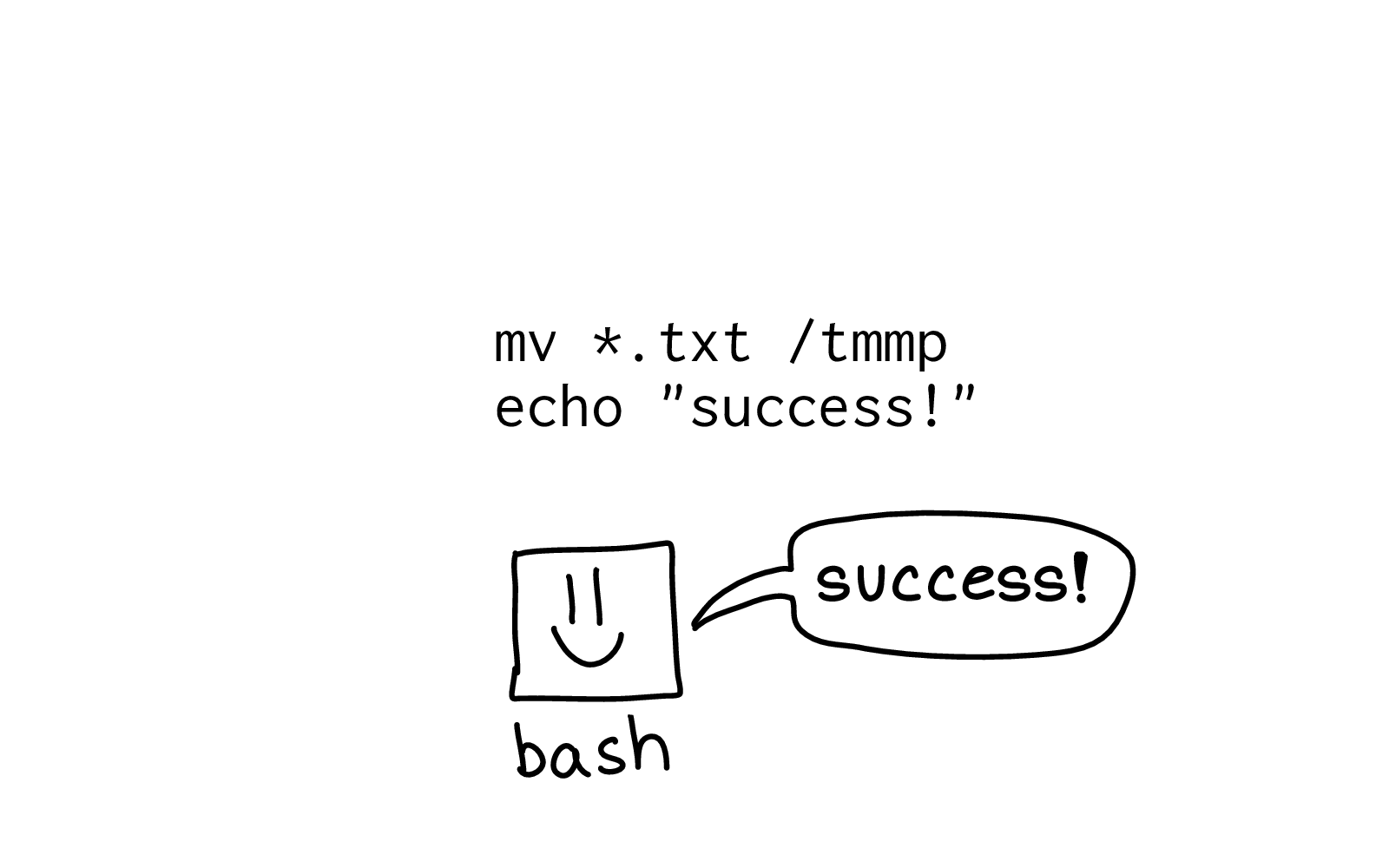
First, let's run this script, bad.sh:
mv ./*.txt /tmmpp echo "success!"
This moves a file and prints "success!". And with most of the programming languages that I use, if there's a problem, the program will stop.
[laughter from audience]
But I think a lot of you know from maybe sad experience that bash does not stop, right? It keeps going. And going… and sometimes very bad things happen to your computer in the process.
When I run this program, here's the output:
mv: cannot stat './*.txt': No such file or directory success!
It didn't stop after the failed mv.

Eventually I learned that you can write set
-e at the top of your program, and that will make bash stop if
there's a problem.
When we run this new program with set -e at the top, here's the output:
mv: cannot stat './*.txt': No such file or directory


Here we've put our code in a function. And if the function fails, we want to echo "failed".
So use set -e at the beginning, and you might think everything should be okay.
But if we run it... this is the output we get
mv: cannot stat './*.txt': No such file or directory success
We get the "success" message again! It didn't stop, it just kept going. This is
because the "or" (|| echo "failed") globally disables set -e in the
function.
Which is certainly not what I wanted, and not what I would expect. But this is not a bug in bash, it's is the documented behavior.

And I think one reason this is tricky is a lot of us don't use bash very often. Maybe you write a bash script every six months and don't look at it again.
When you use a system very infrequently and it's full of a lot of weird trivia and gotchas, it's hard to use the system correctly.

So how can we make this easier? What can we do about it?


But I would say this is factually untrue. How many of you are using bash?
A lot of us ARE using it! And it doesn't always work perfectly, but often it gets the job done.

We have a lot of bash programs that are mostly working, and there’s a big community of us who are using bash mostly successfully despite all the problems.
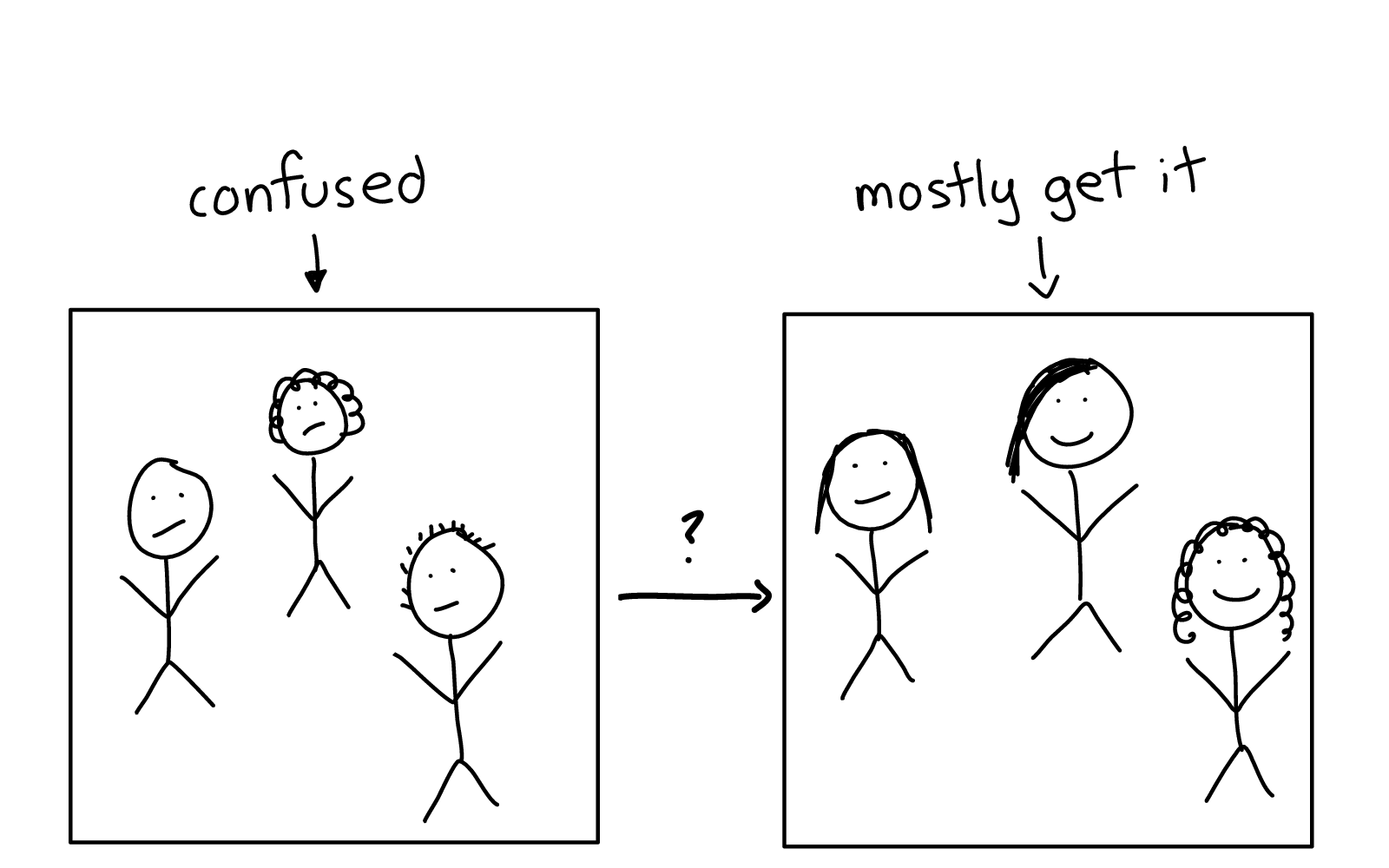
The way I think this is -- you have some people on the left in this diagram who are confused about bash, who think it seems awful and incomprehensible.
And some people on the right who know how to make the bash work for them, mostly.
So how do we move people from the left to the right, from being overwhelmed by a pile of impossible gotchas to being able to mostly use the system correctly?
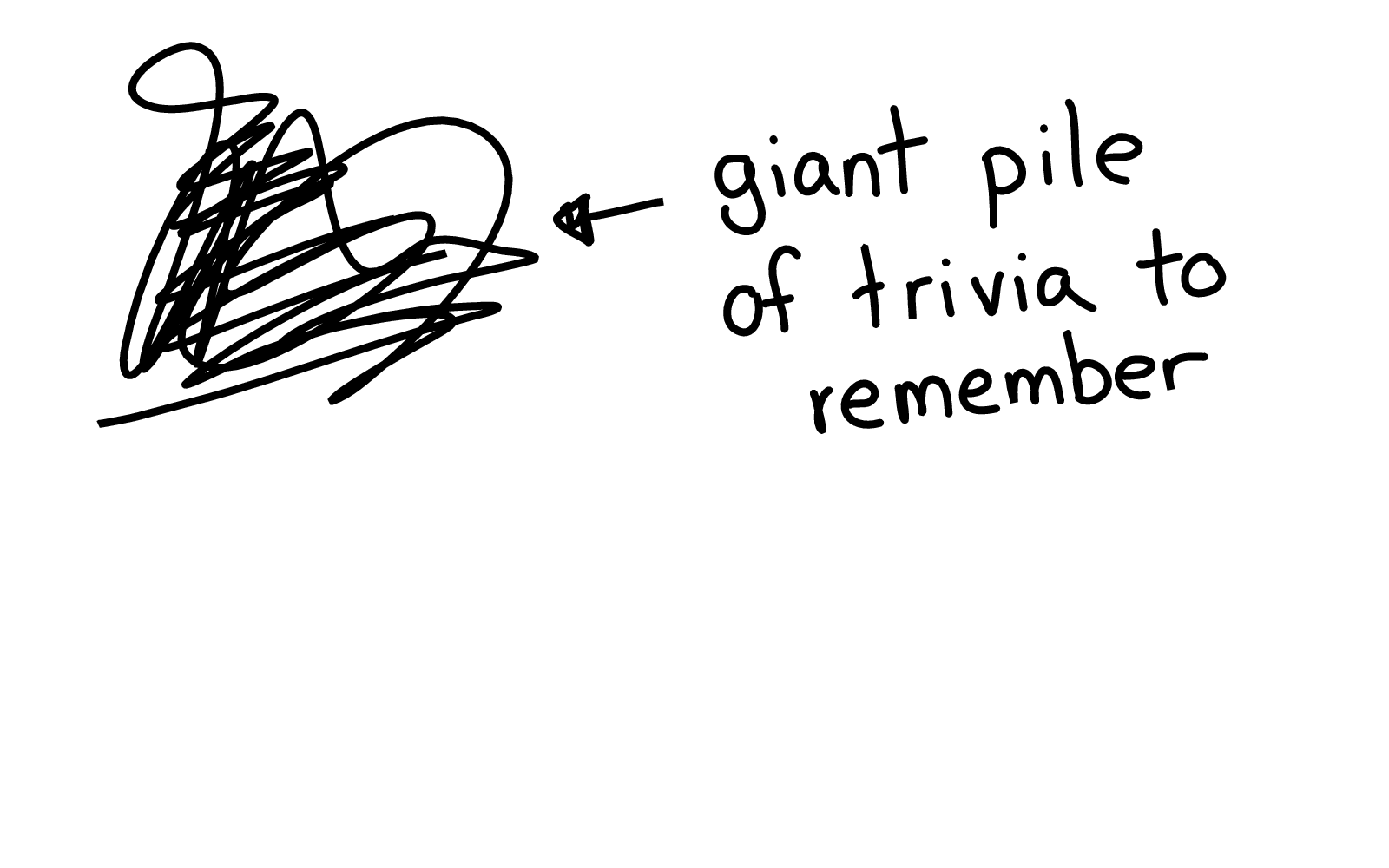
Well, bash has a giant pile of trivia to remember. But who’s good at remembering giant piles of trivia?
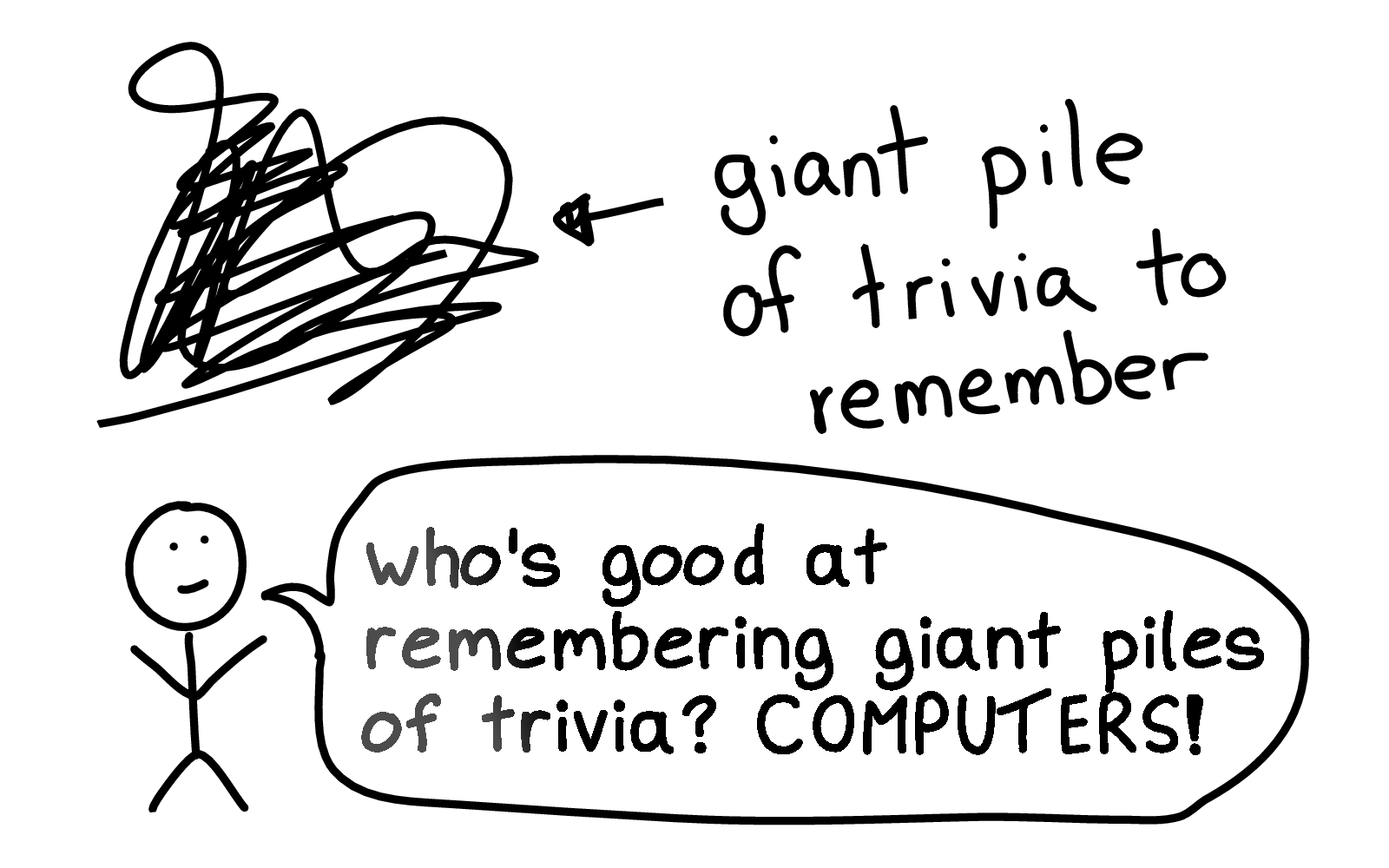
Not me! I can’t memorize all of the weird things about bash. But computers! Computers are great at memorizing trivia!

And for bash, we have this incredible tool called shellcheck.
[ Applause ]
Yes! Shellcheck is amazing! And shellcheck knows a lot of things that can go wrong and can tell you "oh no, you don't want to do that. You're going to have a bad time."
I'm very grateful for shellcheck, it makes it much easier for me to write tiny bash scripts from time to time.

Now let's do a shellcheck demo!
$ shellcheck -o all bad-again.sh In bad-again.sh line 7: f || echo "failed!" ^-- SC2310 (info): This function is invoked in an || condition so set -e will be disabled. Invoke separately if failures should cause the script to exit.
Shellcheck gives us this
lovely error message. The message isn't completely obvious on its own (and this
check is only run if you invoke shellcheck with -o all). But
shellcheck tells you "hey, there's this problem, maybe you should be worried
about that".
And I think it's wonderful that all these tips live in this linter.
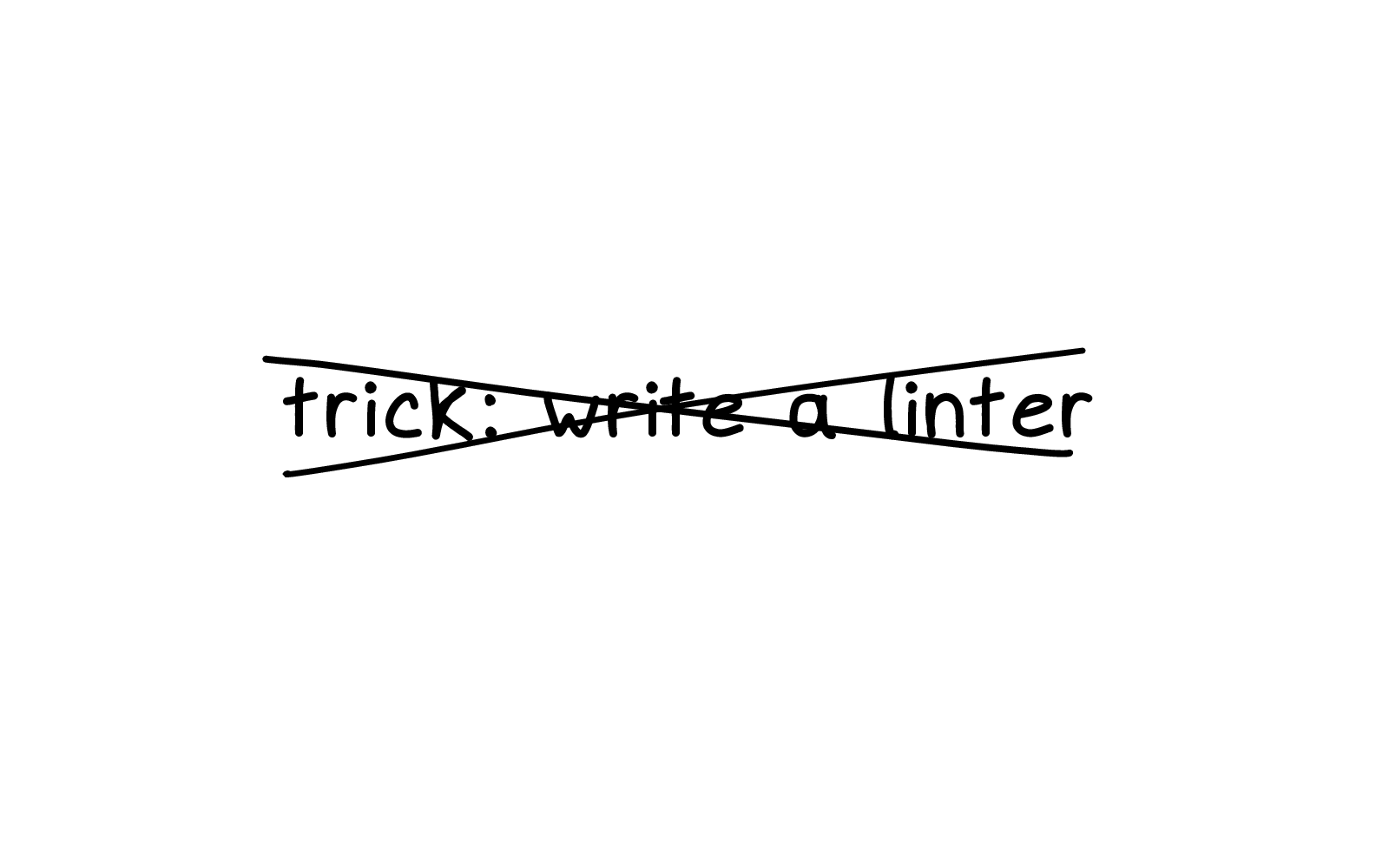
I'm not trying to tell you to write linters, though I think that some of you probably will write linters because this is that kind of crowd.
I've personally never written a linter, and I'm definitely not going to create something as cool as shellcheck!

But instead, the way I write linters is I tell people about shellcheck from time to time and then I feel a little like I invented shellcheck for those people. Because some people didn't know about the tool until I told them about it!
I didn't find out about shellcheck for a long time and I was kind of mad about it when I found out. I felt like -- excuse me? I could have been using shellcheck this whole time? I didn't need to remember all of this stuff in my brain?
So I think an incredible thing we can do is to reflect on the tools that we're using to reduce our cognitive load and all the things that we can't fit into our minds, and make sure our friends or coworkers know about them.

I also like to warn people about gotchas and some of the terrible things computers have done to me.

I think this is an incredibly valuable community service. The example I shared
about how set -e got disabled is something I learned from my
friend Jesse a few weeks ago.
They told me how this thing happened to them, and now I know and I don't have to go through it personally.

One way I see people kind of trying to share terrible things that their computers have done to them is by sharing "best practices".
But I really love to hear the stories behind the best practices!
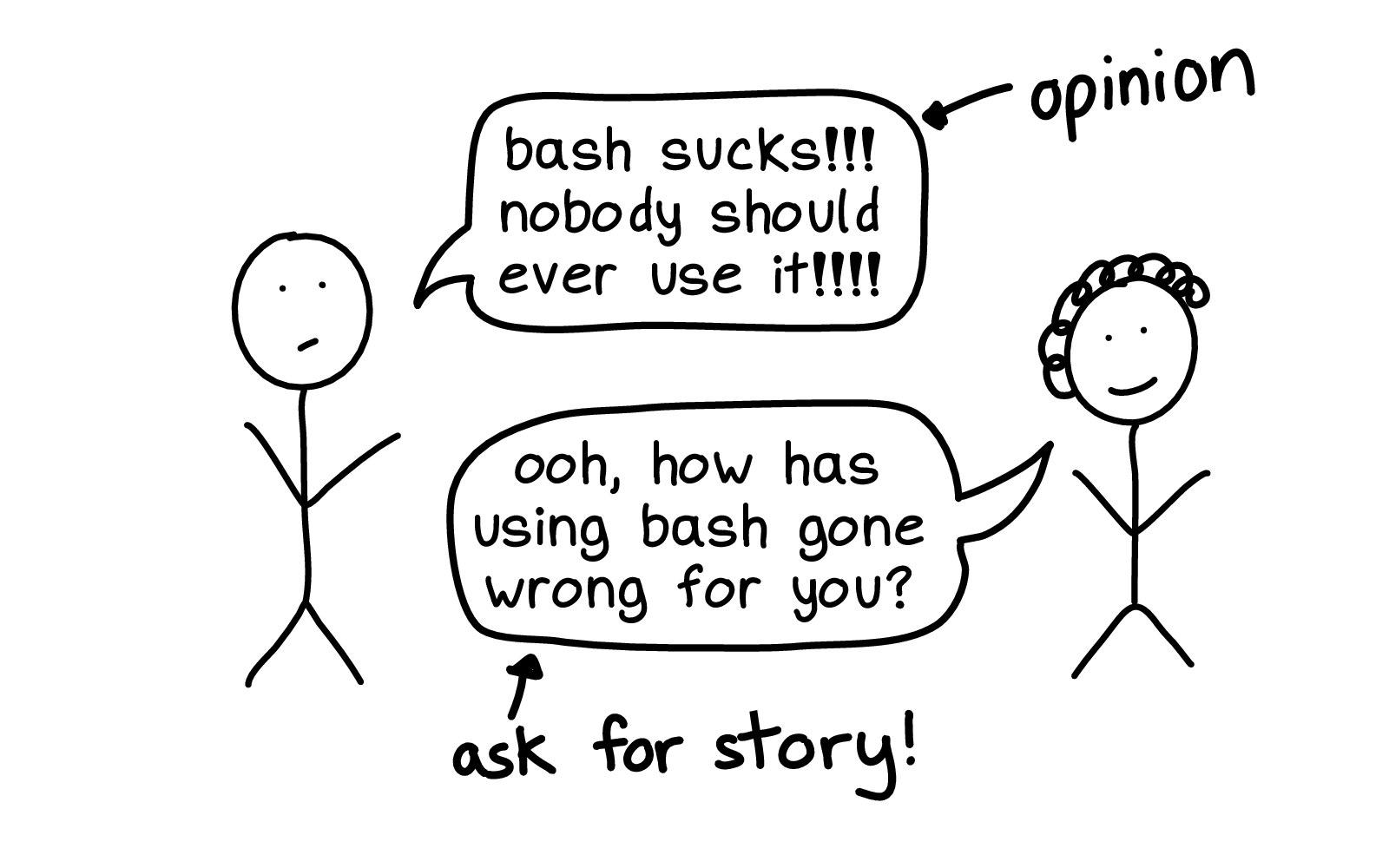
If someone has a strong opinion like "nobody should ever use bash", I want to hear about the story! What did bash do to you? I need to know.
The reason I prefer stories to best practices is if I know the story about how the bash hurt you, I can take that information and decide for myself how I want to proceed.
Maybe I feel like -- the computer did that to you? That's okay, I can deal with that problem, I don't mind.
Or I might instead feel like "oh no, I'm going to do the best practice you recommended, because I do not want that thing to happen to me".
These bash stories are a great example of that: my reaction to them is "okay, I'm going to keep using bash, I'll just use shellcheck and keep my bash scripts pretty simple". But other people see them and decide "wow, I never want to use bash for anything, that's awful, I hate it".
Different people have different reactions to the same stories and that's okay.


I was talking to Marco Rogers at some point, many years ago, and he mentioned some new developers he was working with were struggling with HTTP.
And at first, I was a little confused about this -- I didn't understand what was hard about HTTP.

The way I was thinking about it at the time was that if you have an HTTP response, it has a few parts: a response code, some headers, and a body.
I felt like -- that's a pretty simple structure, what's the problem? But of course there was a problem, I just couldn't see what it was at first.
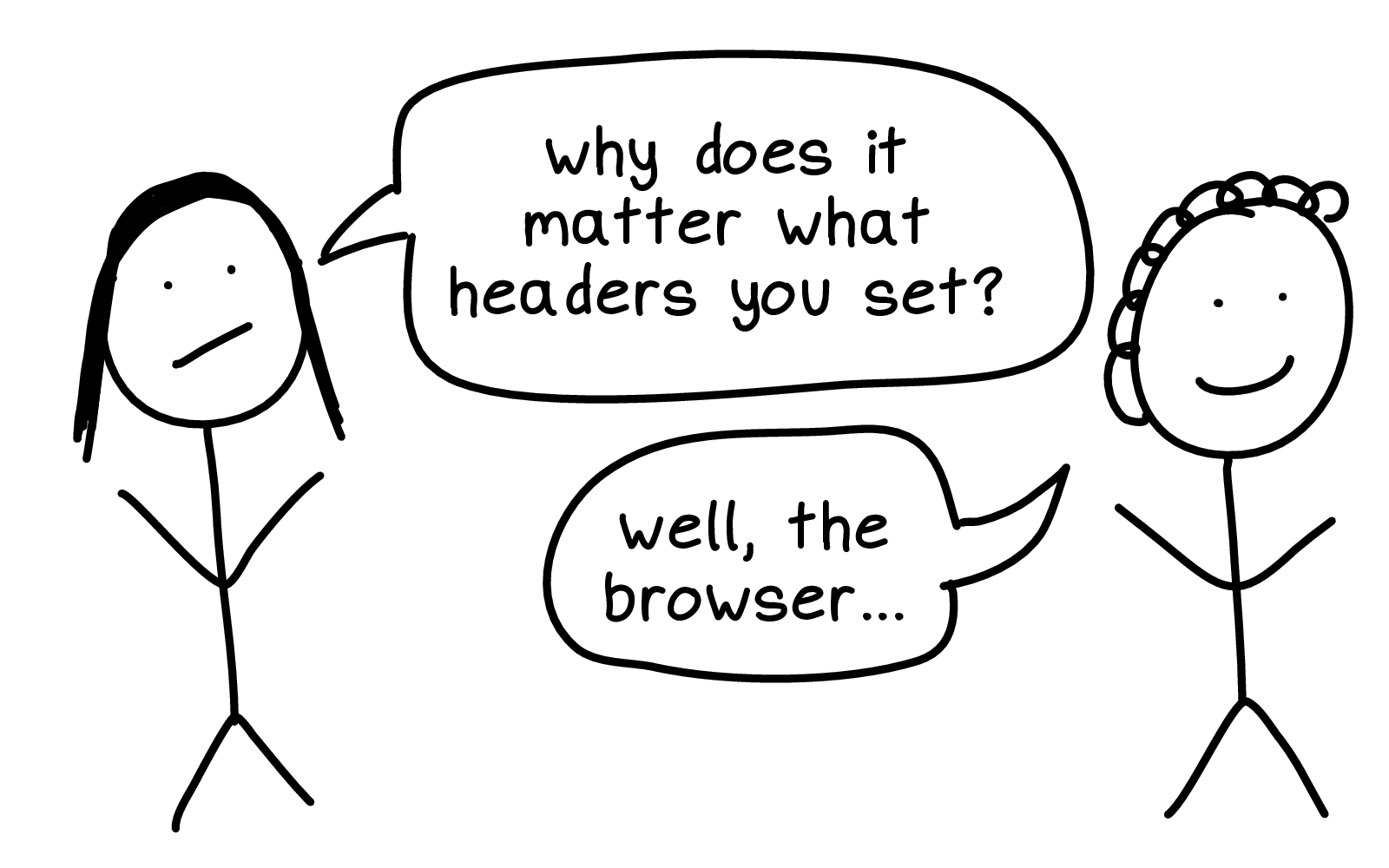
So, I talked to a friend who was newer to HTTP. And they asked "why does it matter what headers you set?"
And I said: "well, the browser..."
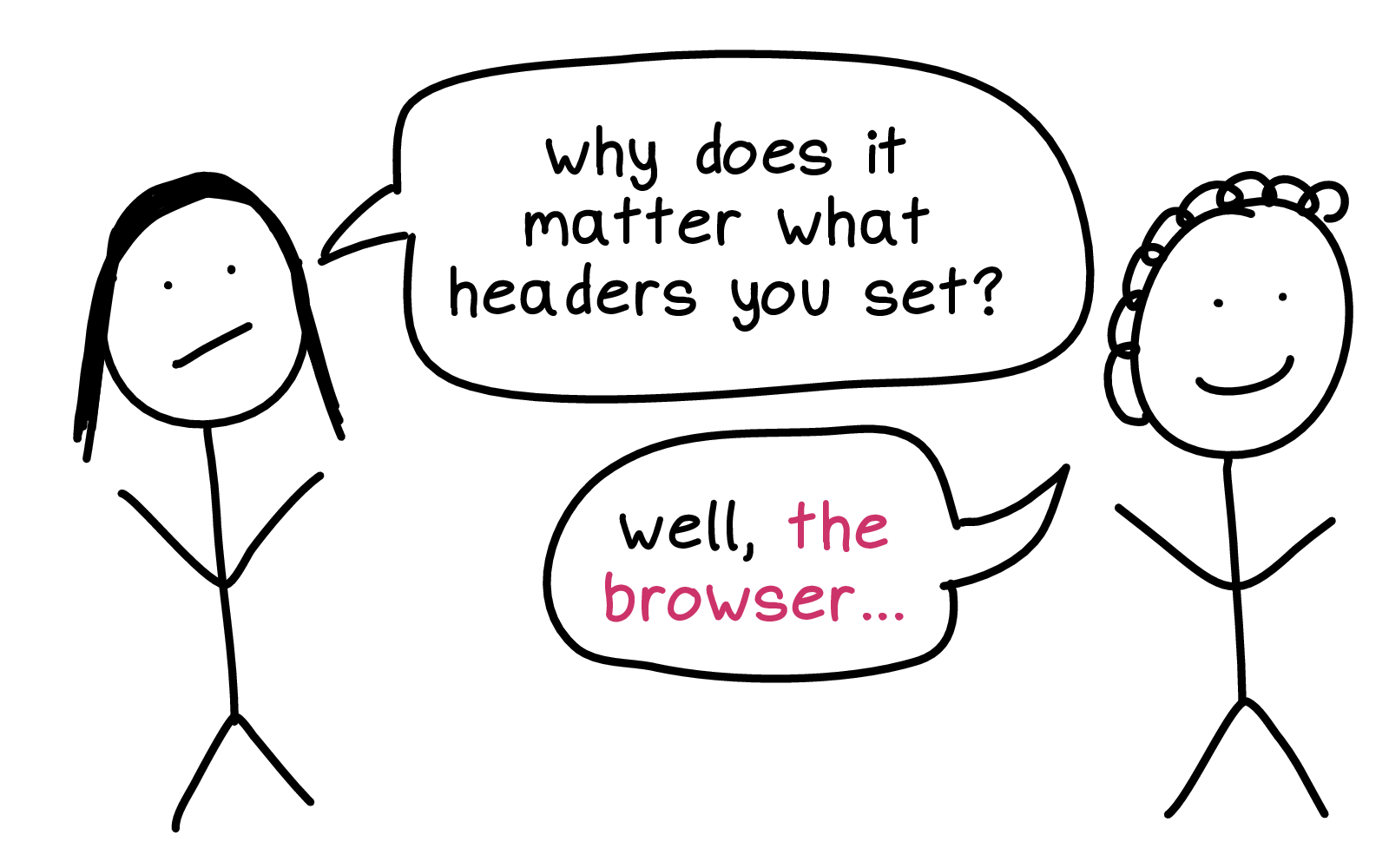

The browser!
Firefox is 20 million lines of code! It's been evolving since the '90s. There have been as I understand it, 1 million changes to the browser security model as people have discovered new and exciting exploits and the web has become a scarier and scarier place.
The browser is really a lot to understand.

One trick for understanding why a topic is hard is -- if the implementation if the thing involves 20 million lines of code, maybe that's why people are confused!
Though that 20 million lines of code also involves CSS and JS and many other things that aren't HTTP, but still.

Once I thought of it in terms of how complex a modern web browser is, it made so much more sense! Of course newcomers are confused about HTTP if you have to understand what the browser is doing!
Then my problem changed from "why is this hard?" to "how do I explain this at all?"
So how do we make it easier? How do we wrap our minds around this 20 million lines of code?

One way I think about this for HTTP is: here are some of the HTTP request headers. That's kind of a big list there are 43 headers there.

There are more unofficial headers too.

My brain does not contain all of those headers, I have no idea what most of them are.
When I think about trying to explain big topics, I think about -- what is actually in my brain, which only contains a normal human number of things?

This is a comic I drew about HTTP request headers. You don't have to read the whole thing. This has 15 request headers.
I wrote that these are "the most important headers", but what I mean by "most important" here is that these are the ones that I know about and use. It's a subjective list.
I wrote about 12 words about each one, which I think is approximately the amount of information about each header that lives in my mind.
For example I know that you can set Accept-Encoding to gzip
and then you might get back a compressed response. That's all I know,
and that's usually all I need to know!
This very small set of information is working pretty well for me.

The general way I think about this trick is "turn a big list into a small list".
Turn the set of EVERY SINGLE THING into just the things I've personally used. I find it helps a lot.

Another example of this "turn a big list into a small list" trick is command line arguments.
I use a lot of command line tools, the number of arguments they have can be overwhelming, and I've written about them a fair amount over the years.

Here are all the flags for grep, from its man page. That's too much! I've been using grep for 20 years but I don't know what all that stuff is.
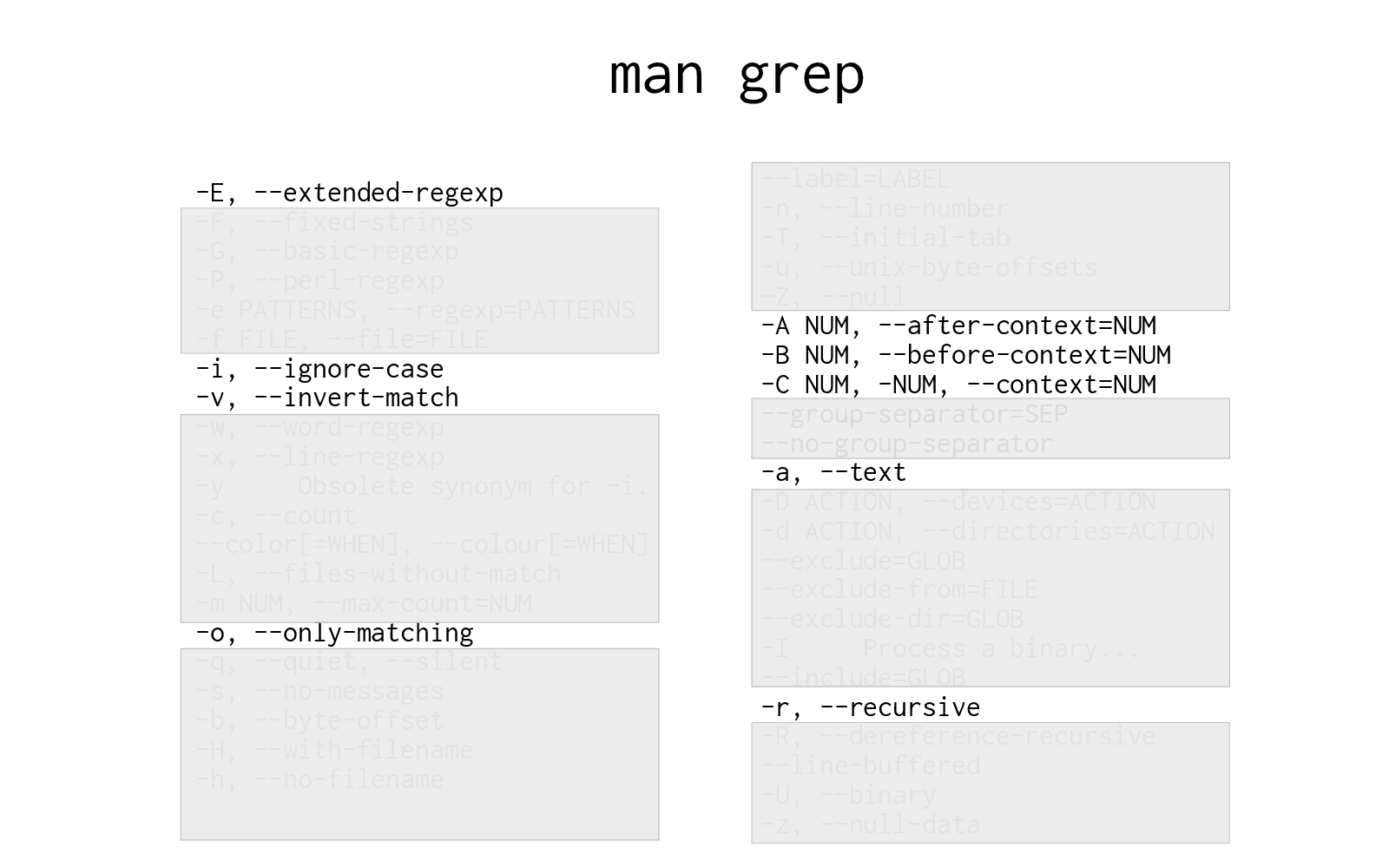
But when I look at the grep man page, this is what I see.
I think it's very helpful to newcomers when a more experienced person says "look, I've been using this system for a while, I know about 7 things about it, and here's what they are".
We're just pruning those lists down to a more human scale. And it can even help other more experienced people -- often someone else will know a slightly different set of 7 things from me.

But what about the stuff that doesn't fit in my brain?
Because I have a few things about HTTP stored in my brain. But sometimes I need other information which is hard to remember, like maybe the exact details of how CORS works.

And so, that’s where we come to references. Where do we find the information that we can’t remember?

I often have trouble finding the right references.
For example I've been trying to learn CSS off and on for 20 years. I've made a lot of progress -- it's going well!
But only in the last 2 years or so I learned about this wonderful website called CSS Tricks.
And I felt kind of mad when I learned about CSS Tricks! Why didn't I know about this before? It would have helped me!
But anyway, I'm happy to know about CSS Tricks now. (though sadly they seem to have stopped publishing in April after the acquisition, I'm still happy the older posts are there)
For HTTP, I think a lot of us use the Mozilla Developer Network.

Another HTTP reference I love is the official RFC, RFC 9110 (also 9111, 9112, 9113, 9114)
It's a new authoritative reference for HTTP and it was written just last
year, in 2022! They decided to organize all the information really nicely. So if you
want to know exactly what the Connection header does, you can look
it up.
This is not really my top reference. I'm usually on MDN. But I really appreciate that it's available.
So I love to share my favorite references.

I do sometimes find it tempting to kind of lie about references. Not on purpose. But I'll see something on the internet, and I'll think it's kind of cool, and tell a friend about. But then my friend might ask me -- "when have you used this?" And I'll have to admit "oh, never, I just thought it seemed cool".
I think it's important to be honest about what the references that I'm actually using in real life are. Even if maybe the real references I use are a little "embarrassing", like maybe w3schools or something.

So that’s HTTP! Next we’re going to talk about SQL.

I started thinking about SQL because someone mentioned they're trying to learn SQL. I get most of my zine ideas that way, one person will make an offhand comment and I'll decide "ok, I'm going to spend 4 months writing about that". It's a weird process.
So I was wondering -- what's hard about SQL? What gets in the way of trying to learn that?
I want to say that when I'm confused about what's hard about something, that's a fact about me. It's not usually that the thing is easy, it's that I need to work on understanding what's hard about it. It's easy to forget when you've been using something for a while.

So, I was used to reading SQL queries. For example this made up query that tries to find people who own exactly two cats. It felt straightforward to me, SELECT, FROM, WHERE, GROUP BY.

But then I was talking to a friend about these queries who was new to SQL. And my friend asked -- what is this doing?
I thought, hmm, fair point.

And I think the point my friend was making was that the order that this SQL query is written in, is not the order that it actually happens in. It happens in a different order, and it's not immediately obvious what that is.

So how do we make this easier?

I like to think about: what does the computer do first? What actually happens first chronologically?
Computers actually do live in the same timeline as us. Things happen. Things happen in an order. So what happens first?


The way I think about an SQL query is: is you start with a table like
cats.

Then maybe you filter it, you remove some stuff.

Then you make some groups.
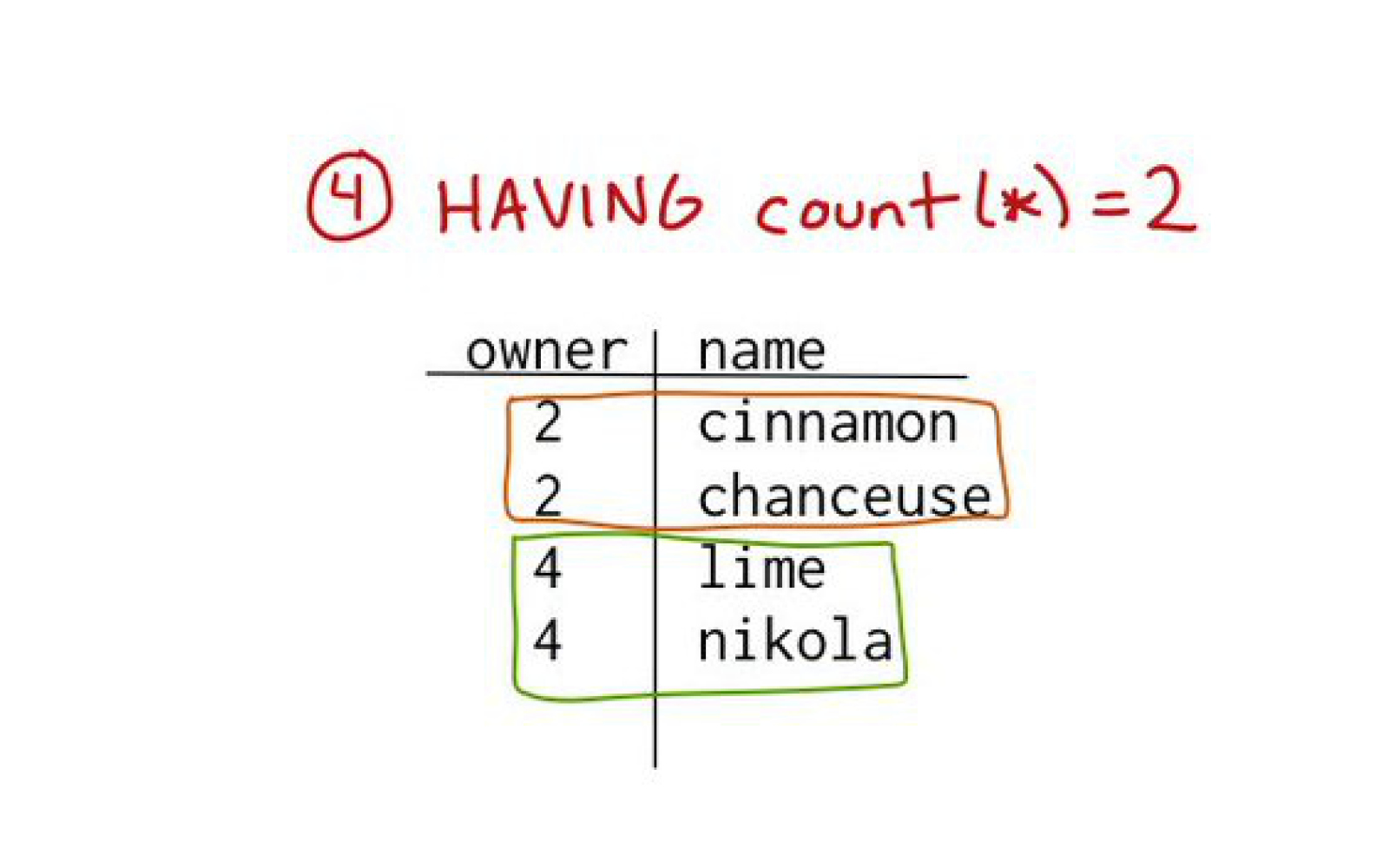
Then you filter the groups, remove some of them.

Then you do some aggregation. There’s two things in each group.

And you sort it.
And you can also limit the results.

So, that's how I think about SQL. The way a query runs is first FROM, then WHERE, GROUP BY, HAVING, SELECT, ORDER BY, LIMIT.
At least conceptually. Real life databases have optimizations and it's more complicated than that. But this is the mental model that I use most of the time and it works for me. Everything is in the same order as you write it, except SELECT is fifth.

I’ve really gotten a lot out of this trick where you try to tell the chronological story of what the computer is doing. I want to talk about a couple other examples.

One is CORS, in HTTP.
This comic is way too small to read on the slide. But the idea is if you're making a cross-origin request in your browser, you can write down every communication that's happening between your browser and the server, in chronological order.
And I think writing down everything in chronological order makes it a lot easier to understand and more concrete.

"What happens in chronological order?" is a very straightforward structure, which is what I like about it. "What happens first?" feels like it should be easy to answer. But it's not!
I've found that it's actually very hard to know what our computers is doing, and it's a really fun question to explore.

As an example of how this is hard: I wrote a blog post recently called "Behind Hello World on Linux". It's about what happens when you run "hello world" on a Linux computer. I wrote a bunch about it, and I was really happy with it.
But after I wrote the post, I thought -- haven't I written about this before? Maybe 10 years ago?

And sure enough, I'd tried to write a similar post 10 years before.
I think this is really cool. Because the 2013 version of this post was about 6 times shorter. This isn't because Linux is more complicated than it was 10 years ago -- I think everything in the 2023 post was probably also true in 2013. The 2013 post just has a lot less information in it.
The reason the 2023 post is longer is that I didn't know what was happening chronologically on my computer in 2013 very well, and in 2023 I know a lot more. Maybe in 2033 I'll know even more!
I think a lot of us -- like me in 2013 and honestly me now, often don't know the facts of what's happening on our computers. It's very hard, which is what makes it such a fun question to try and discuss.

I think it's cool that all of us have different knowledge about what is happening chronologically on our computers and we can all chip in to this conversation.
For example when I posted this blog post about Hello World on Linux, some people mentioned that they had a lot of thoughts about what happens exactly in your terminal, or more details about the filesystem, or about what's happening internally in the Python interpreter, or any number of things. You can go really deep.
I think it's just a really fun collaborative question.

I've seen "what happens chronologically?" work really well as an activity with coworkers, where you're ask: "when a request comes into this API endpoint we run, how does that work? What happens?"
What I've seen is that someone will understand some part of the system, like "X happens, then Y happens, then it goes over to the database and I have no idea how that works". And then someone else can chime in and say "ah, yes, with the database A B C happens, but then there's a queue and I don't know about that".
I think it's really fun to get together with people who have different specializations and try to make these little timelines of what the computers are doing. I've learned a lot from doing that with people.


So, now we’ve arrived at DNS which is where we started the talk.

Even though I struggled with DNS. Once I got figured it out, I felt like "dude, this is easy!". Even though it just took me 10 years to learn how it works.
But of course, DNS was pretty hard for me to learn. So -- why is that? Why did it take me so long?
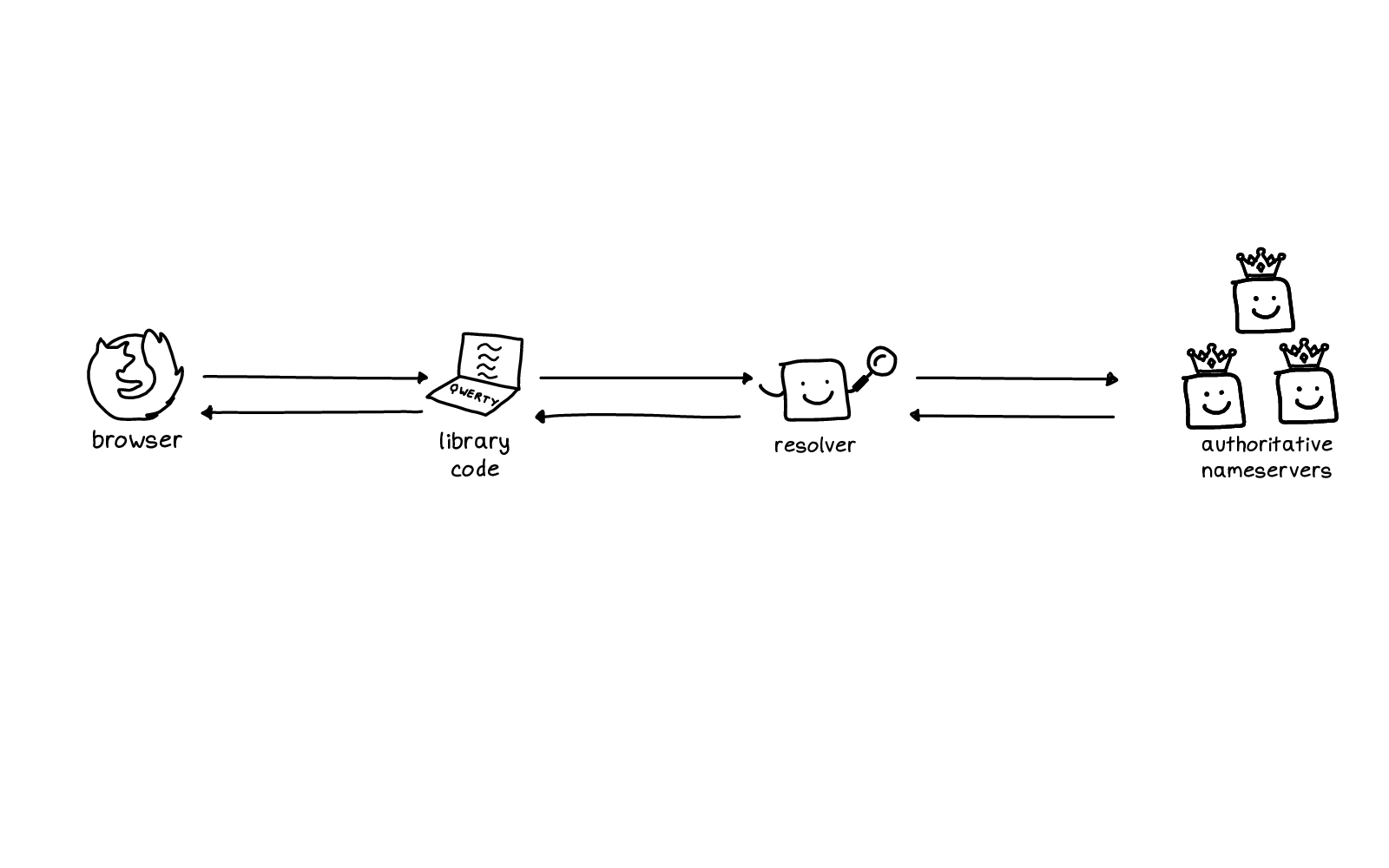
So, I have a little chart here of how I think about DNS.
You have your browser on the left. And over on the right there's the authoritative nameservers, the source of truth of where the DNS records for a domain live.
In the middle, there's a function that you call and a cache. So you have browser, function, cache, source of truth.
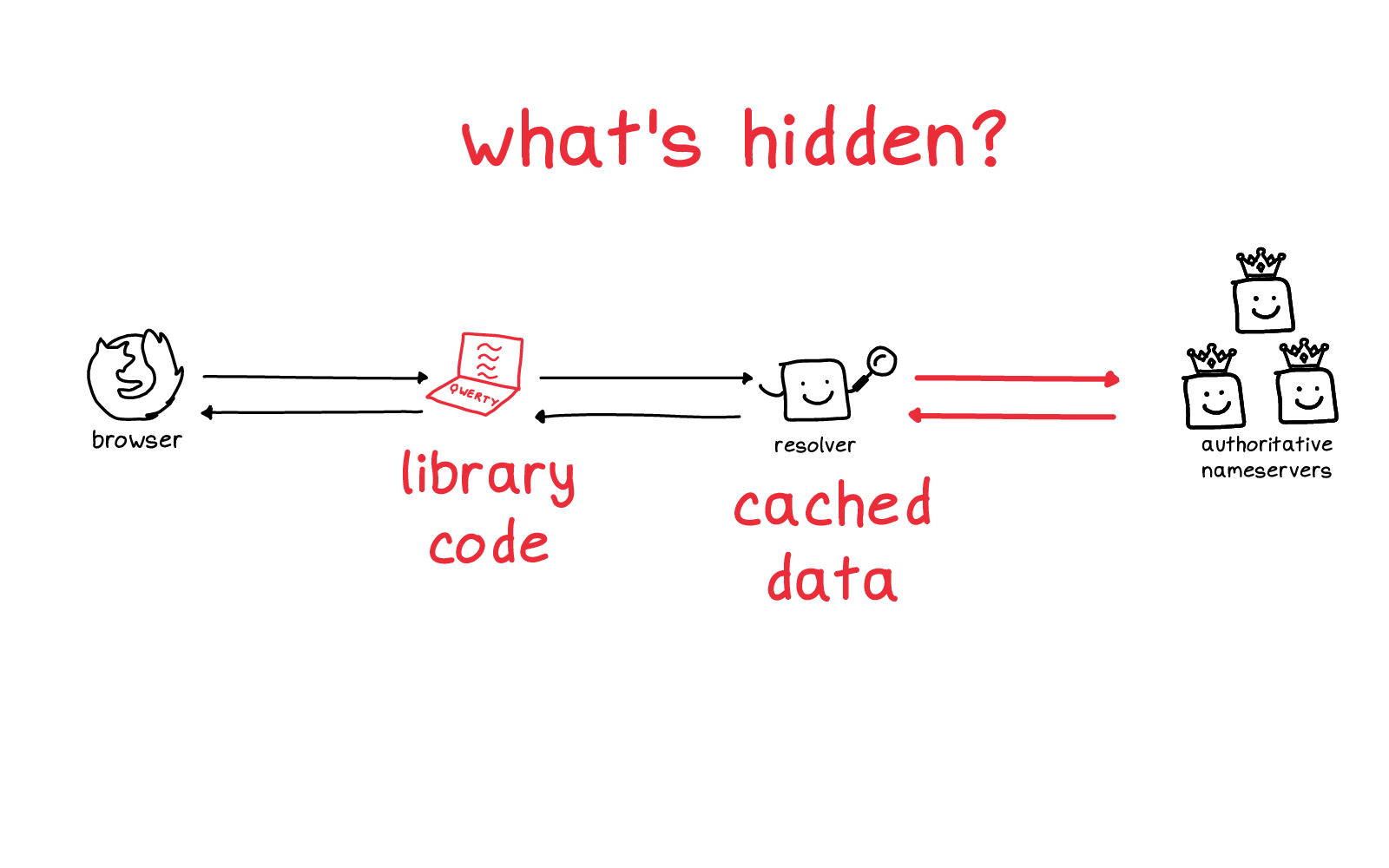
One problem is that there are a lot of things in this diagram that are totally hidden from you.
The library code that you're using where you make a DNS request -- there are a lot of different libraries you could be using, and it's not straightforward to figure out which one is being used. That was the source of some of my confusion.
There's a cache which has a bunch of cached data. That's invisible to you, you can't inspect it easily and you have no control over it. that
And there's a conversation between the cache and the source of truth, these two red arrows which also you can't see at all.
So this is kind of tough! How are you supposed to develop an intuition for a system when it's mostly things that are completely hidden from you? Feels like a lot to expect.

So, what do we do about this?
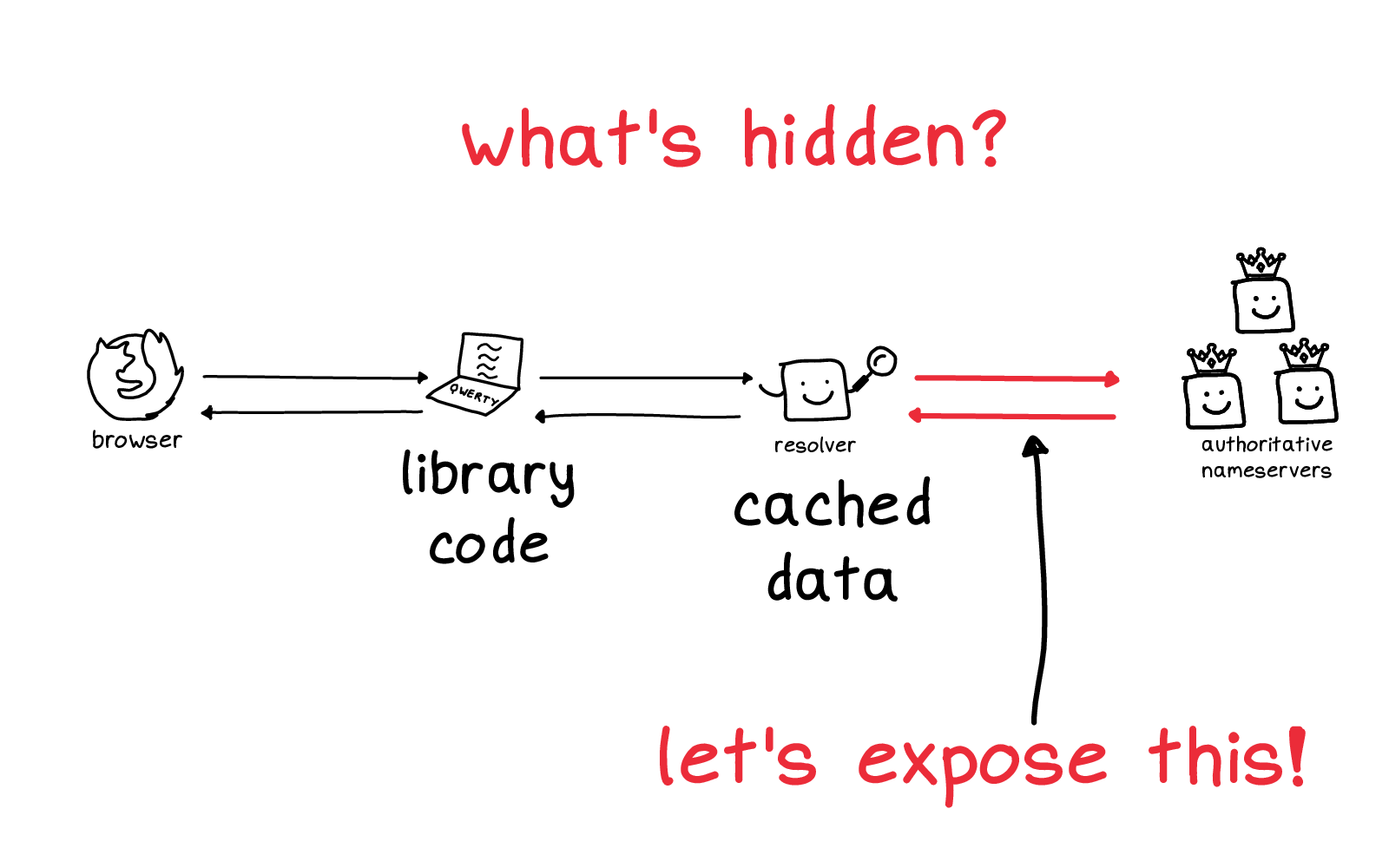
So: let's talk about these red arrows on the right.
We have our cache and then we have the source of truth. This conversation is normally hidden from you because you often don't control either of these servers. Usually they're too busy doing high-performance computing to report to you what they're doing.
But I thought: anyone can write an authoritative nameserver! In particular, I could write one that reports back every single message that it receives to its users. So, with my friend Marie, we wrote a little DNS server.

(demo of messwithdns.net)
This is called Mess With DNS. The idea is I have a domain name and you
can do whatever you want with it. We're going to make a DNS record called
strangeloop, and we're going to make a CNAME record pointing at
orange.jvns.ca, which is just a picture of an orange. Because I
like oranges.
And then over here, every time a request comes in from a resolver, this will -- this will report back what happened. So, if we click on this link, we can see -- a Canadian DNS resolver, which is apparently what my browser is configured to use, is requesting an IPv4 record and an IPv6 record, A and AAAA.
(at this point in the demo everyone in the audience starts visiting the link and it gets a bit chaotic, it’s very funny)

So the trick here is to find ways to show people parts of what the computer is doing that are normally hidden.

Another great example of showing things that are hidden is this website called float.exposed by Bartosz Ciechanowski who makes a lot of incredible visualizations.
So if you look at this 32-bit floating point number and click the "up" button on the significand, it'll show you the next floating point number, which is 2 more. And then as you make the number bigger and bigger (by increasing the exponent), you can see that the floating point numbers get further and further apart.
Anyway, this is not a talk about floating point. I could do an entire talk about this site and how we can use it to see how floating point works, but that's not this talk.

Another thing that makes DNS confusing is that it's a giant distributed system -- maybe you're confused because there are 5 million computers involved (really, more!). Most of which you have no control over, and some are doing not what they're supposed to do.
So that's another trick for understanding why things are hard, check to see if there are actually 5 million computers involved.

So what else is hard about DNS?
We've talked about how most of the system is hidden from you, and about how it's a big distributed system.

One problem I’ve run into is that the tools are confusing.
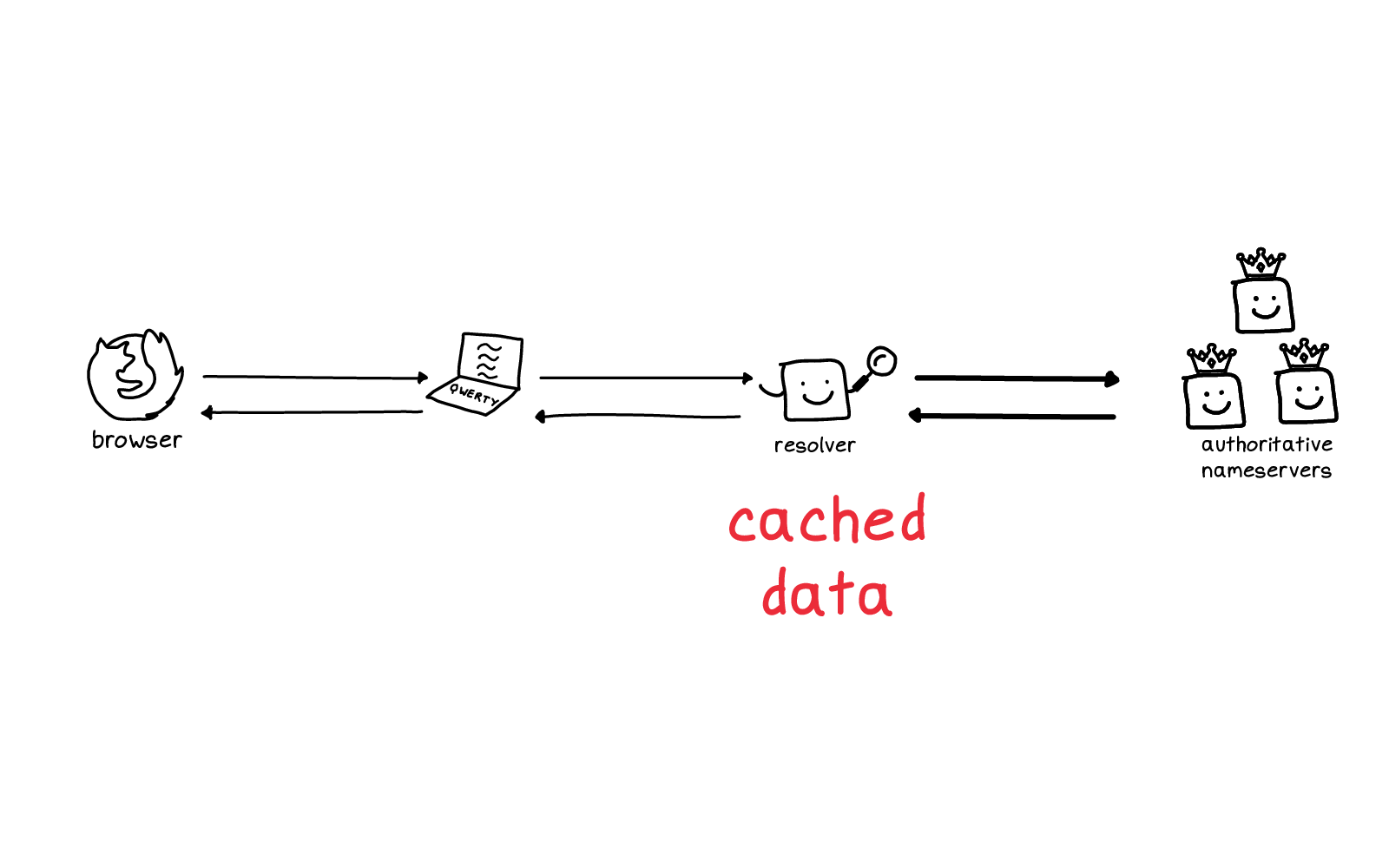
One of the hidden things I talked about was: the resolver has cached data, right? And you might be curious about whether a certain domain name is cached or not by your resolver right now.
Just to understand what's happening: am I getting this result because it was cached? What's the deal?
I said this was hidden, but there are a couple of ways to query a resolver to see what it has cached, and I want to show you one of them.

The tool I usually use for making DNS queries is called dig, and
it has a flag called +norecurse. You can use it to query a
resolver and ask it to only return results it already has cached.
With dig +norecurse jvns.ca, I'm kind of asking -- how popular is my website? Is it popular enough that someone has visited it in the last 5 minutes?
Because my records are not cached for that long, only for 5 minutes.

But when I look at this response, I feel like "please! What is all this?"
And when I show newcomers this output, they often respond by saying "wow, that's complicated, this DNS thing must be really complicated". But really this is just not a great output format, I think someone just made some relatively arbitrary choices about how to print this stuff out in the 90s and it's stayed that way ever since.
So a bad output format can mislead newcomers into thinking that something is more complicated than it actually is.

What can we do about confusing output like this?

One of my favorite tricks, I call eraser eyes.
Because when I look at that output, I'm not looking at all of it, I'm just looking at a few things. My eyes are ignoring the rest of it.
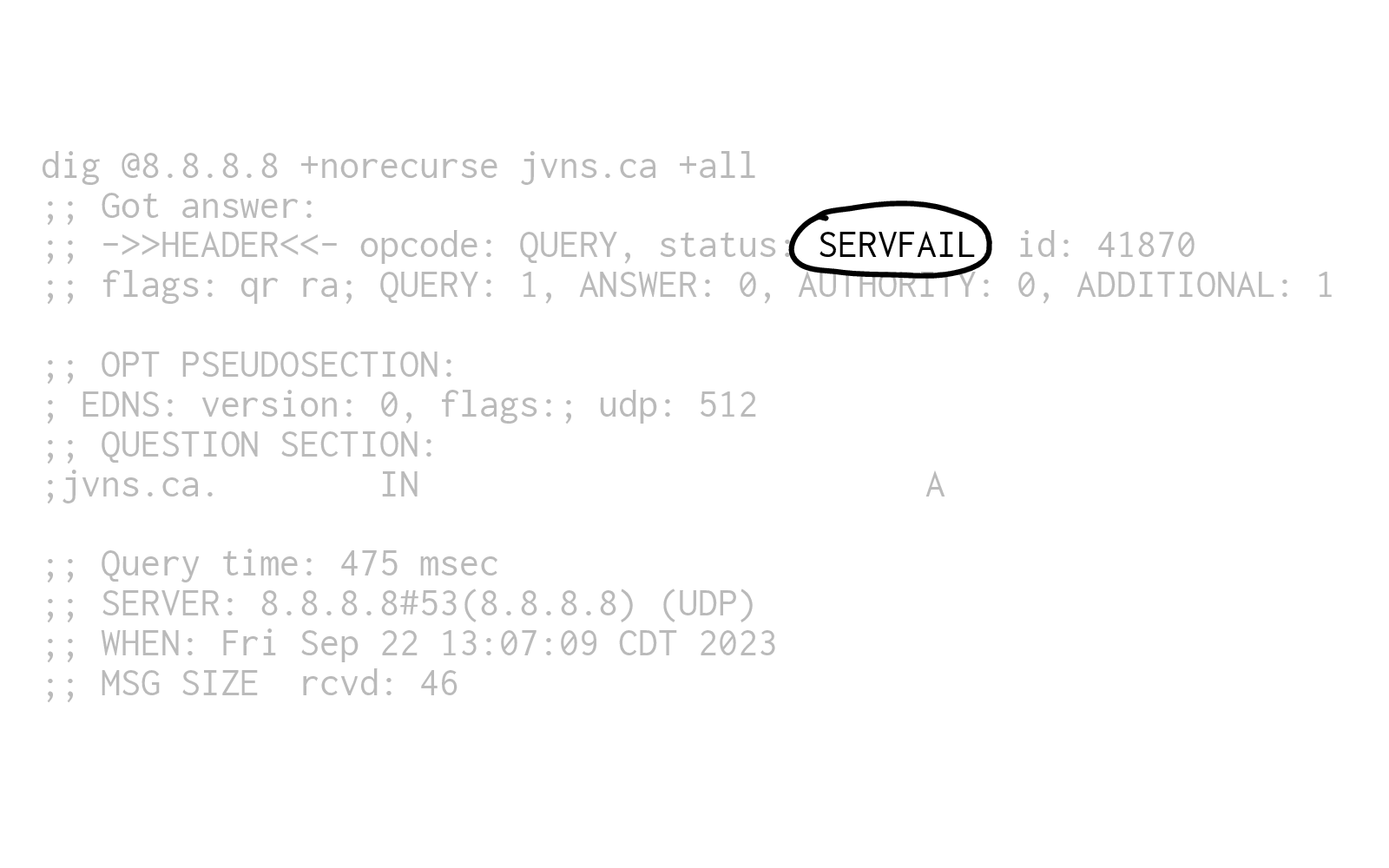
When I look at the output, this is what I see: it says SERVFAIL.
That's the DNS response code.
Which as I understand it is a very unintuitive way of it saying, "I do not have that in my cache". So nobody has asked that resolver about my domain name in the last 5 minutes, which isn't very surprising.
I've learned so much from people doing a little demo of a tool, and showing how they use it and which parts of the output or UI they pay attention to, and which parts they ignore.
Becuase usually we ignore most of what's on our screens!
I really love to use dig even though it's a little hairy because
it has a lot of features (I don't know of another DNS debugging that supports this
+norecurse trick), it's everywhere, and it hasn't changed in a
long time. And I know if I learn its weird output format once I can know that
forever. Stability is really valuable to me.

So we’ve talked about these four technologies. Let’s talk a little more about how we can make things easier for each other.
What can we do to move folks from “I really don’t get it” to “okay, I can mostly deal with this, at least 90% of the time, it’s fine”? For bash or HTTP or DNS or anything else.

We've talked about some tricks I use to bring people over, like:
- sharing useful tools
- sharing references
- telling a chronological story of what happens on your computer
- turning a big list into a small list of the things you actually use
- showing the hidden things
- demoing a confusing tool and telling folks which parts I pay attention to

When I practiced this talk, I got some feedback from people saying “julia! I don’t do those things! I don’t have a blog, and I’m not going to start one!”
And it's true that most people are probably not going to start programming blogs.

But I really don't think you need to have a public presence on the internet to tell the people around you a little bit about how you use computers and how you understand them.

My experience is that a lot of people (who do not have blogs!) have helped me understand how computers work and have shared little pieces of their experience with computers with me.
I've learned a lot from my friends and my coworkers and honestly a lot of random strangers on the Internet too. I'm pretty sure some of you here today have helped me over the years, maybe on Twitter or Mastodon.
So I want to talk about some archetypes of helpful people

One kind of person who has really helped me is the grumpy old-timer. I'll say "this is so cool". And they'll reply yes, however, let me tell you some stories of how this has gone wrong in my life.
And those stories have sometimes helped spare me some suffering.

We have the loud newbie, who asks questions like "wait, how does that work?" And then everyone else feels relieved -- "oh, thank god. It's not just me."
I think it's especially valuable when the person who takes the "loud newbie" role is actually a pretty senior developer. Because when you're more secure in your position, it's easier to put yourself out there and say "uh, I don't get this" because nobody is going to judge you for that and think you're incompetent.
And then other people who feel more like they might be judged for not knowing something can ride along on your coattails.

Then we have the bug chronicler. Who decides "ok, that bug. This can never happen again".
"I'm gonna make sure we understand what happened. Because I want this to end now."

We have the tool builder, whose attitude is more like “I see people struggling with something, and I don’t feel like explaining it. But I can write code to just make it easier permanently for everyone.”

There’s this “today I learned” person who’s into sharing cool new tools they learned about, a bug that they ran into, or a great new-to-them library feature.

There’s the person who has read the entire Internet and has 700 tabs open. If you want to know where to find something, there’s a good chance they already have it open in their browser.

We have the person who is just willing to answer questions! “Yeah, I can tell you how that works!”

And at the end of all this, sometimes you have someone who likes to write some things down so that other people can read it and can find it later.
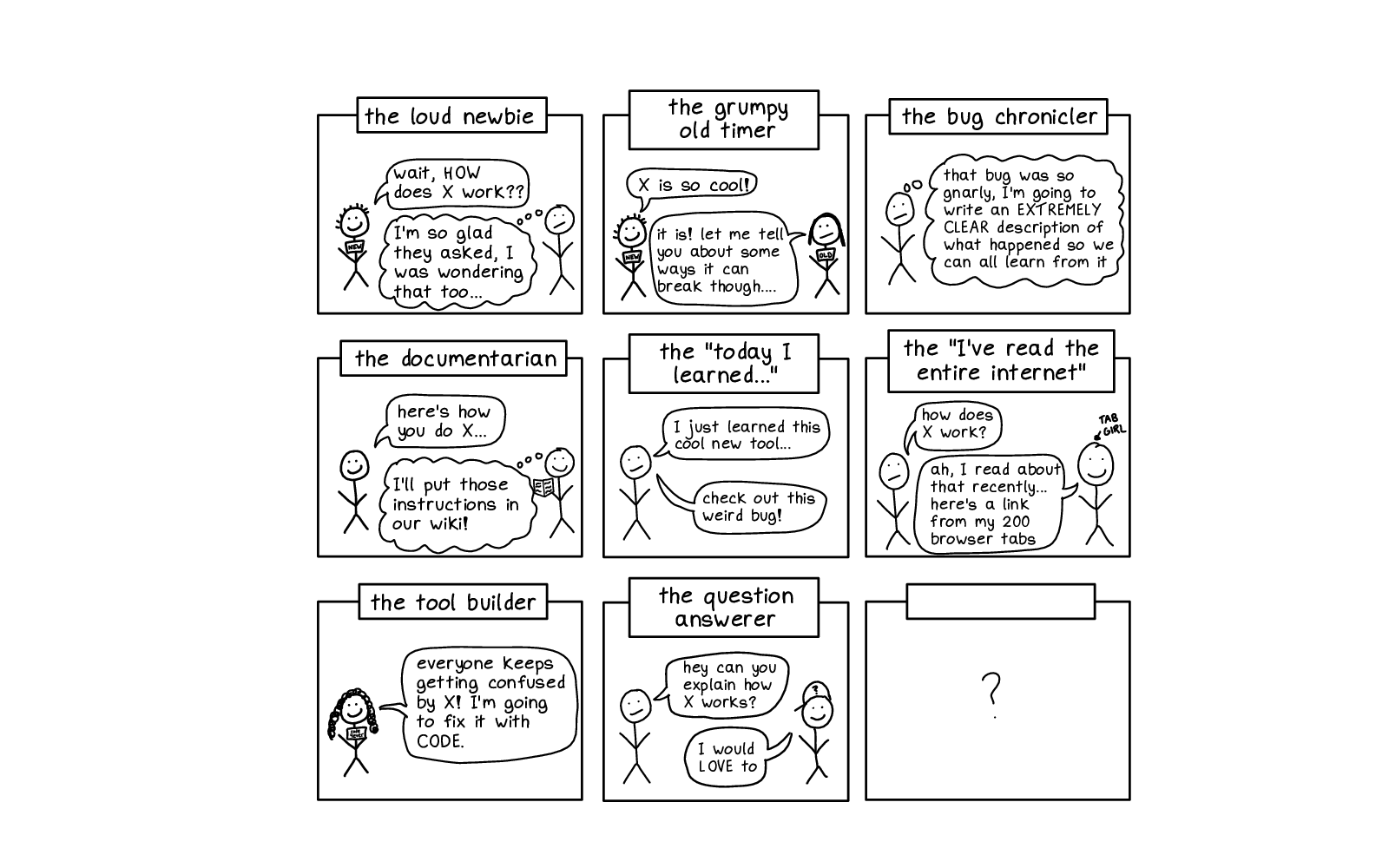
But all of us have different roles and we need to work together. I’m into writing but a lof of the stuff I’ve written about, I only know about because someone told me about it or explained it to me.

To end: the one thing I would like to convince you of is: if you’re struggling with something that feels basic, it’s not just you! You’re not alone. We’re all struggling with a lot of these things that feel like they should be “basic”.

And we’re struggling with these things for a lot of the same reasons as each other.

And much like when debugging a computer program, when you have a bug, you want to understand why the bug is happening if you're gonna fix it.
If we're all struggling with the same things together for the same reasons, if we can figure out what those reasons are, we can do a better job of fixing them.

Some of the reasons we’ve talked about were:
- a giant pile of trivia and gotchas.
- or maybe there's 20 million lines of code somewhere.
- Maybe a big part of the system is being hidden from you.
- Maybe the tool's output is extremely confusing and no UI designer has ever worked on improving it
And there are a lot more reasons.
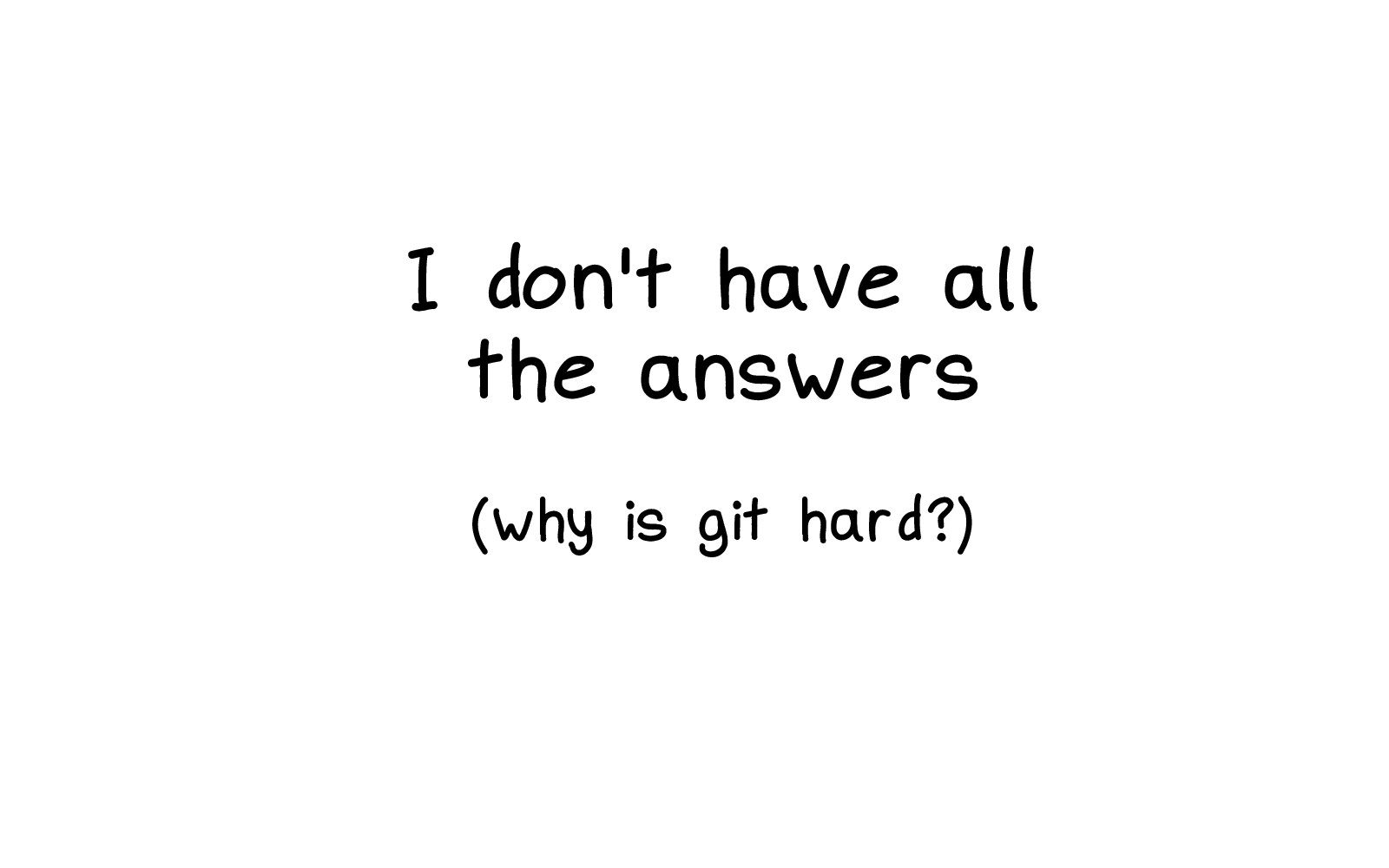
I don’t have all the answers for why things are hard. For example I don’t really understand why Git is hard, that’s something I’ve been thinking about recently.

But that’s something I’m excited to keep working on and keep trying to figure out.

And that's all I have for you. Thank you.
I brought some zines to the conference, if you come to the signing later on you can get one.
some thanks
This was the last ever Strange Loop and I’m really grateful to Alex Miller and the whole organizing team for making such an incredible conference for so many years. Strange Loop accepted one of my first talks (you can be a kernel hacker) 9 years ago when I had almost no track record as a speaker so I owe a lot to them.
Thanks to Sumana for coming up with the idea for this talk, and to Marie, Danie, Kamal, Alyssa, and Maya for listening to rough drafts of it and helping make it better, and to Dolly, Jesse, and Marco for some of the conversations I mentioned.
Also after the conference Nick Fagerland wrote a nice post with thoughts on why git is hard in response to my “I don’t know why git is hard” comment and I really appreciated it. It had some new-to-me ideas and I’d love to read more analyses like that.