"I just want to run a container!"
I wrote “what’s up with containers: Docker and rkt” a while ago. Since then I have learned a few new things about containers! We’re going to talk about running containers in production, not on your laptop for development, since I’m trying to understand how that works in September 2016. It’s worth noting that all this stuff is moving pretty fast right now.
The concerns when you run containers in production are pretty different from running it on a laptop – I very happily use Docker on my laptop and I have no real concerns about it because I don’t care much if processes on my laptop crash like 0.5% of the time, and I haven’t seen any problems.
Here are the things I’ve learned so far. I learned many of these things with @grepory who is the best. Basically I want to talk about what some of the things you need to think about are if you want to run containers, and what is involved in “just running a container” :)
At the end I’m going to come back to a short discussion of Docker’s current architecture. (tl;dr: @jpetazzo wrote a really awesome gist)
Docker is too complicated! I just want to run a container
So, I saw this image online! (comes from this article)
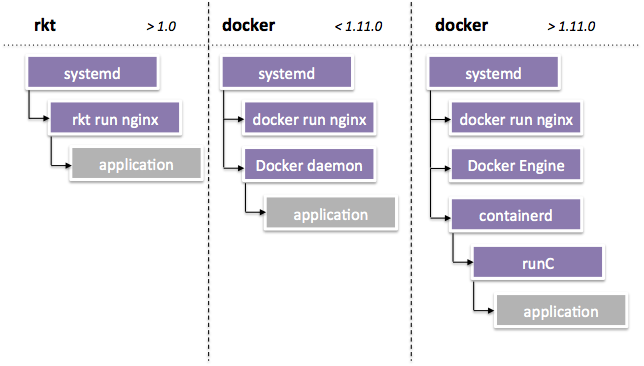
And I thought “that rkt diagram looks way easier to operate in production! That’s what I want!”
Okay, sure! No problem. I can use runC! Go to runc.io, follow the
direction, make a config.json file, extract my container into a tarball, and now I can
run my container with a single command. Awesome.
Actually I want to run 50 containers on the same machine.
Oh, okay, that’s pretty different. So – let’s say all my 50 containers share a bunch of files (shared libraries like libc, Ruby gems, a base operating system, etc.). It would be nice if I could load all those files into memory just once, instead of 3 times.
If I did this I could save disk space on my machine (by just storing the files once), but more importantly, I could save memory!
If I’m running 50 containers I don’t want to have 50 copies of all my shared libraries in memory. That’s why we invented dynamic linking!
If you’re running just 2-3 containers, maybe you don’t care about a little bit of copying. That’s for you to decide!
It turns out that the way Docker solves this is with “overlay filesystems” or “graphdrivers”. (why are they called graphdrivers? Maybe because different layers depend on each other like in a directed graph?) These let you stack filesystems – you start with a base filesystem (like Ubuntu 14.04) and then you can start adding more files on top of it one step at a time.
Filesystem overlays need some Linux kernel support to work – you need to use a filesystem that supports them. The Brutally Honest Guide to Docker Graphdrivers by the fantastic Jessie Frazelle has a quick overview. overlayfs seems to be the most normal option.
At this point, I was running Ubuntu 14.04. 14.04 runs a 3.13 Linux kernel! But to use overlayfs, you need a 3.18 kernel! So you need to upgrade your kernel. That’s fine.
Back to runC. runC does not support overlay filesystems. This is an intentional design choice – it lets runC run on older kernels, and lets you separate out the concerns. But it’s not super obvious right now how to use runC with overlay filesystems. So what do I do?
I’m going to use rkt to get overlay filesystem support
So! I’ve decided I want overlay filesystem support, and gotten a Linux kernel newer than 3.18. Awesome. Let’s try rkt, like in that diagram! It lives at coreos.com/rkt/
If you download rkt and run rkt run docker://my-docker-registry/container, This
totally works. Two small things I learned:
--net=host will let you run in the host network namespace
Network namespaces are one of the most important things in container land. But if you want to run containers using as few new things as possible, you can start out by just running your containers as normal programs that run on normal ports, like any other program on your computer. Cool
--exec=/my/cool/program lets you set which command you want rkt to execute inside the image
systemd: rkt will run a program called systemd-nspawn as the init (PID 1) process inside your container. This is because it can be bad to run an arbitrary process as PID 1 – your process isn’t expecting it and will might react badly. It also run some systemd-journal process? I don’t know what that’s for yet.
The systemd journal process might act as a syslog for your container, so that programs sending logs through syslog end up actually sending them somewhere.
There is quite a lot more to know about rkt but I don’t know most of it yet.
I’d like to trust that the code I’m running is actually my code
So, security is important. Let’s say I have a container registry. I’d like to make sure that the code I’m running from that registry is actually trusted code that I built.
Docker lets you sign images to verify where they came from. rkt lets you run Docker images. rkt does not let you check signatures from Docker images though! This is bad.
You can fix this by setting up your own rkt registry. Or maybe other things! I’m going to leave that here. At this point you probably have to stop using Docker containers though and convert them to a different format.
Supervising my containers (and let’s talk about Docker again)
So, I have this Cool Container System, and I can run containers with overlayfs and I can trust the code I’m running. What now?
Let’s go back to Docker for a bit. So far I’ve been a bit dismissive about Docker, and I’d like to look at its current direction a little more seriously. Jérôme Petazzoni wrote an extremely informative and helpful discussion about how Docker got to its architecture today in this gist. He says (which I think is super true) that Docker’s approach to date has done a huge amount to drive container adoption and let us try out different approaches today.
The end of that gist is a really good starting point for talking about how “start new containers” should work.
Jérôme very correctly says that if you’re going to run containers, you need a way to tell boxes which containers to run, and supervise and restart containers when they die. You could supervise them with daemontools, supervisord, upstart, or systemd, or something else!
“Tell boxes which containers to run” is another nontrivial problem and I’m not going to talk about it at all here. So, back to supervision.
Let’s say you use systemd. Then that’ll look like (from the diagram I posted at the top):
- systemd -+- rkt -+- process of container X
| \- other process of container X
+- rkt --- process of container Y
\- rkt --- process of container Z
I don’t know anything about systemd, but it’s pretty straightforward to tell daemontools “hey, here’s a new process to start running, it’s going to run a container”. Then daemontools will restart that container process if it crashes. So this is basically fine.
My understanding of the problem with Docker in production historically is that – the process that is responsible for this core functionality of process supervision was the Docker engine, but it also had a lot of other features that you don’t necessarily want running in production.
The way Docker seems to be going in the future is something like: (this diagram is from jpetazzo’s gist above)
- init - containerd -+- shim for container X -+- process of container X
| \- other process of container X
+- shim for container Y --- process of container Y
\- shim for container Z --- process of container Z
where containerd is a separate tool, and the Docker engine talks to containerd but isn’t as heavily coupled to it. Right now containerd’s website says it’s alpha software, but they also say on their website that it’s used in current versions of Docker, so it’s not totally obvious what the state is right now.
the OCI standard
We talked about how runC can run containers just fine, but cannot do overlay filesystems or fetch + validate containers from a registry. I would be remiss if I didn’t mention the OCID project that @grepory told me about last week, which aims to do those as separate components instead of in an integrated system like Docker.
Here’s the article: Red Hat, Google Engineers Work on a Way for Kubernetes to Run Containers Without Docker .
Today there’s skopeo which lets you fetch and validate images from Docker registries
what we learned
here’s the tl;dr:
- you can run Docker containers without Docker
- runC can run containers… but it doesn’t have overlayfs
- but overlay filesystems are important!
- rkt has overlay filesystem support.
- you need to start & supervise the containers! You can use any regular process supervisor to do that.
- also you need to tell your computers which containers to run
- software around the OCI standard is evolving but it’s not there yet
As far as I can tell running containers without using Docker or Kubernetes or anything is totally possible today, but no matter what tools you use it’s definitely not as simple as “just run a container”. Either way going through all these steps helps me understand what the actual components of running a container are and what all these different pieces of software are trying to do.
This landscape is pretty confusing but I think it’s not impossible to understand! There are only a finite number of different pieces of software to figure out the role of :)
If you want to see more about running containers from scratch, see Cgroups, namespaces, and beyond: what are containers made from? by jpetazzo. There’s a live demo of how to run a container with 0 tools (no docker, no rkt, no runC) at this point in the video which is super super interesting.
Thanks to Jérôme Petazzoni for answering many questions and to Kamal Marhubi for reading this.