Today I did the opening keynote at SRECon. This talk was a little less technical than my normal talks: instead of talking about tools like tcpdump (though tcpdump makes an appearance!), I wanted to talk about how to make a career where you’re constantly learning and how to be good at your job whether or not you’re the most experienced person.
Here’s the video, talk abstract, then the slides & a rough transcript. I’ve included links to every resource I mentioned.
video
abstract
I don't always feel like a wizard. I'm not the most experienced member on my team, like most people I sometimes find my work difficult, and I still have a TON TO LEARN.
But along the way, I have learned a few ways to debug tricky problems, get the information I need from my colleagues, and get my job done. We're going to talk about
At the end, we'll have a better understanding of how you can get a lot of awesome stuff done even when you're not the highest level wizard on your team.
- how asking dumb questions is actually a superpower
- how you can read the source code to programs when all other avenues fail
- debugging tools that make you FEEL like a wizard
- and how understanding what your _organization_ needs can make you amazing
So you want to be a wizard
(this transcript is nowhere near totally faithful; there’s a fair amount of “what i meant to say / what I said, kind of, I think” in here :) )
You can click on any of the slides to see a bigger version.


This talk is called "so you want to be a wizard". The main problem with being a wizard is that, of course, computers are not magic! They are logical machines that you can totally learn to understand.

So this talk is actually going to be about learning hard things and understanding complicated systems.

I work as an engineer at Stripe. (this is the job description for my job).

My team is in charge of a ton of things. Every so often I find out about a new thing that we're in charge of ("oh, there's a GPG keyserver we depend on? Okay!!")

What this means is that I (like many of you!) need to know about a ton of different systems. There are about a million things to know about Linux & networking, the AWS platform is really complicated and there's a ton to know about how it works exactly.
And there's a seemingly neverending amount of new technology to learn about. For instance we're looking at Kubernetes, and to operate a Kubernetes cluster you need to operate etcd, which means that you need to understand a bunch of distributed systems concepts to make sure you're doing it right.
And there's a seemingly neverending amount of new technology to learn about. For instance we're looking at Kubernetes, and to operate a Kubernetes cluster you need to operate etcd, which means that you need to understand a bunch of distributed systems concepts to make sure you're doing it right.

So to do my job effectively, like many of you, I need to constantly learn new things. This talk is about how to do that, and why I like it.

Here are the wizard skills we're going to be discussing in this talk!

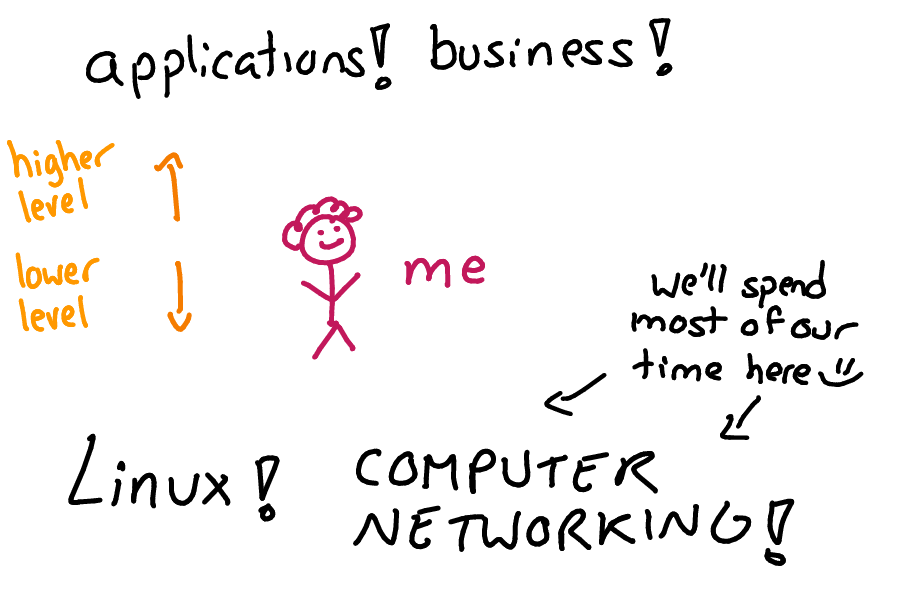
In software engineering, I think it's really important to understand both the systems that are a little higher-level than you and lower-level systems.
In reliability engineering, what lives below us is typically "systems stuff" like operating systems & networking. Above us is stuff like business requirements & the programs we're trying to make run reliably.
This talk is mostly going to be about understanding lower-level systems, but we're also going to talk a little about humans and how to make sure you're actually building the right thing :)
In reliability engineering, what lives below us is typically "systems stuff" like operating systems & networking. Above us is stuff like business requirements & the programs we're trying to make run reliably.
This talk is mostly going to be about understanding lower-level systems, but we're also going to talk a little about humans and how to make sure you're actually building the right thing :)
As a quick aside, I think understanding computer networking is so important that I wrote a whole zine about it, which you can pick up at the end of this talk.

So -- why is it important to understand the systems you work with?

I think there are 3 main important reasons:
First, understanding jargon is really useful. If someone says "hey, this process got killed by the OOM killer" it's useful to know what that means! (we're going to talk about what an OOM killer is later)
second, it lets you debug harder problems. When I set up a web server (Apache) for the first time, maybe 8 years ago, I didn't understand the HTTP protocol very well and I didn't understand what many of the configuration options I was using meant exactly.
So I would normally debug by Googling things and trying random fixes. This was a pretty viable strategy at the time (I got my webservers working!) but today when I configure webservers, it's important for me to actually understand what I'm doing and exactly what effect I expect it to have. And now I can fix problems much more easily.
rachelbythebay is a great collection of debugging stories, and it's clear throughout that she has a really deep understanding of the systems she works with.
The last reason is -- having a solid understanding of the systems you work with lets you innovate. I think Docker is a cool example of this. Docker was not the first thing to ever use namespaces (one of the kernel features that people call "containers"), but in order to make a tool that people loved to use, the Docker developers had to have a really good understanding of exactly what features Linux has to support isolating processes from others.
First, understanding jargon is really useful. If someone says "hey, this process got killed by the OOM killer" it's useful to know what that means! (we're going to talk about what an OOM killer is later)
second, it lets you debug harder problems. When I set up a web server (Apache) for the first time, maybe 8 years ago, I didn't understand the HTTP protocol very well and I didn't understand what many of the configuration options I was using meant exactly.
So I would normally debug by Googling things and trying random fixes. This was a pretty viable strategy at the time (I got my webservers working!) but today when I configure webservers, it's important for me to actually understand what I'm doing and exactly what effect I expect it to have. And now I can fix problems much more easily.
rachelbythebay is a great collection of debugging stories, and it's clear throughout that she has a really deep understanding of the systems she works with.
The last reason is -- having a solid understanding of the systems you work with lets you innovate. I think Docker is a cool example of this. Docker was not the first thing to ever use namespaces (one of the kernel features that people call "containers"), but in order to make a tool that people loved to use, the Docker developers had to have a really good understanding of exactly what features Linux has to support isolating processes from others.
A system like Linux seems really intimidating at first, especially if you want to understand some of the internals a little bit. It's like 4 million or 10 million lines of code or something.

So let's talk about how to break off pieces of knowledge one at a time so that you can tackle the challenge!

My first favorite thing to do is learn fundamental concepts.
This is incredibly useful -- in networking, if you know what a packet is and how it's put together, then it really helps to tackle other more complicated concepts.
Let me tell you a quick story about how I learned what a system call was.
This is incredibly useful -- in networking, if you know what a packet is and how it's put together, then it really helps to tackle other more complicated concepts.
Let me tell you a quick story about how I learned what a system call was.

The Recurse Center is a 12 week programming retreat in New York where you can go to learn fun new things about programming. I went 3 years ago. RC is about learning whatever interests you (low level stuff? fancy frontend tricks? functional programming? making cool art with programming?), and I went partly with the goal of understanding operating systems better.
When I got to RC, I learned about the concept of a "system call"! (here's the blog post I wrote the day I learned that). System calls are how applications talk to the operating system. I felt kind of sad that I didn't know about them before, but the important thing was that I learned it! That's exciting!
When I got to RC, I learned about the concept of a "system call"! (here's the blog post I wrote the day I learned that). System calls are how applications talk to the operating system. I felt kind of sad that I didn't know about them before, but the important thing was that I learned it! That's exciting!

This is the only piece of homework in this talk :)
TCP is the protocol that runs a lot of the internet that we use day to day. Often it "just works" and you don't need to think about it, but sometimes, well, we do need to think about it! So it's helpful to understand the basics.
The way I started learning about TCP was, I wrote a TCP stack in Python! This was really fun, it didn't take that long, and I learned a ton by doing it and writing up what I learned.
TCP is the protocol that runs a lot of the internet that we use day to day. Often it "just works" and you don't need to think about it, but sometimes, well, we do need to think about it! So it's helpful to understand the basics.
The way I started learning about TCP was, I wrote a TCP stack in Python! This was really fun, it didn't take that long, and I learned a ton by doing it and writing up what I learned.
I also like to do experiments.

You can make your laptop run out of memory on purpose! I would show you what happens (remember the "OOM killer"? it's a system in the Linux kernel that starts just killing programs on your computer!), but I think it might not be a good live demo for a talk :).
I think doing this kind of experiment is awesome because servers run out of memory in production, and it's cool to see what that looks like and how to reason about it in a safer environment. (hint: if you run "dmesg" and search for "oom" it will show you OOM killer activity)
I think doing this kind of experiment is awesome because servers run out of memory in production, and it's cool to see what that looks like and how to reason about it in a safer environment. (hint: if you run "dmesg" and search for "oom" it will show you OOM killer activity)

Also at the Recurse Center, I decided I wanted to write a tiny operating system in Rust. It turns out that writing an OS in 3 weeks when you don't know Rust or operating systems is hard, so I ended up writing a keyboard driver.
I learned SO MUCH by doing this -- you can read more about it here
I learned SO MUCH by doing this -- you can read more about it here


These are the programming experiment rules I like to follow.
Sometimes I like to read books! Two books I've learned from in the last couple years are Networking for System Administrators & Linux Kernel Development.
Networking for System Administrators is written for system administrators who want to be able to do basic networking tasks without having to ask their networking team. I'm not a system administrator, and I don't have a networking team, but I learned a ton by reading this book.

Another thing that I find super helpful is to try to read things or watch talks that are too hard for me at the time. For example, aphyr has an amazing series of posts about distributed systems failures (the ones called "Jepsen"). When I started reading these posts, I honestly didn't understand them very well. I didn't understand what "linearizable" meant, and I'd never worked with distributed databases. So sometimes I'd read a post and only understand maybe 20% of it.
As I learned more and came back to his writing, I was able to understand more of it! I'm still not a distributed systems expert, but I'm happy I tried to read these posts even when I didn't understand them well.
That Linux kernel development book I mentioned is kind of similar. Its goal is to give you the tools you need to become a Linux kernel developer. I am not a Linux kernel developer (or at least not yet!). But I've learned a few interesting things by reading this book.
As I learned more and came back to his writing, I was able to understand more of it! I'm still not a distributed systems expert, but I'm happy I tried to read these posts even when I didn't understand them well.
That Linux kernel development book I mentioned is kind of similar. Its goal is to give you the tools you need to become a Linux kernel developer. I am not a Linux kernel developer (or at least not yet!). But I've learned a few interesting things by reading this book.

Another maybe obvious tactic is to work with the thing in your job. Recently I needed to add some logging to a HTTP proxy we had. This was a relatively mundane task, but I learned more about how HTTP proxies work exactly by doing it! That was cool!
It's useful for me to remember that I can learn something even when I'm doing work which is sort of routine.
It's useful for me to remember that I can learn something even when I'm doing work which is sort of routine.
This is the last, and maybe most important thing. I have models of how a ton of systems work in my head. Sometimes what happens on the computers work with does not match what my model says!
As a small example -- recently we had a computer that was swapping even though it had 16GB of free memory. This did not match my mental model ("computers only swap memory to disk when they're out of memory"). Obviously there was something wrong with my model. So I investigated, and I learned a couple new things about how swap works on Linux!
As a small example -- recently we had a computer that was swapping even though it had 16GB of free memory. This did not match my mental model ("computers only swap memory to disk when they're out of memory"). Obviously there was something wrong with my model. So I investigated, and I learned a couple new things about how swap works on Linux!

It turns that there are actually at least 4 reasons a Linux box might swap.
1. You could be actually out of RAM.
2. You could be "mostly" out of RAM. The "vm.swappiness" sysctl setting controls how likely your machine is to swap. This isn't what was happening to us, though.
3. A cgroup could be out of RAM, which was what was happening to us at the time (here's the blog post I wrote about that).
4. There's also a 4th reason I learned about afterwards: if you have no swap, and your vm.overcommit_ratio is set to 50% (which is the default), you can end up in a situation where only half your RAM can be used. That's no good! here's a post about overcommit on Linux
1. You could be actually out of RAM.
2. You could be "mostly" out of RAM. The "vm.swappiness" sysctl setting controls how likely your machine is to swap. This isn't what was happening to us, though.
3. A cgroup could be out of RAM, which was what was happening to us at the time (here's the blog post I wrote about that).
4. There's also a 4th reason I learned about afterwards: if you have no swap, and your vm.overcommit_ratio is set to 50% (which is the default), you can end up in a situation where only half your RAM can be used. That's no good! here's a post about overcommit on Linux

So it turns out understanding swap isn't actually that simple. In fact, there's a cool 200-page book Understanding the Linux Virtual Memory Manager. It also has a bunch of annotated kernel code that handles memory management, which is awesome.
I'm happy I dug in a bit because now I understand how this part of Linux works better!
I'm happy I dug in a bit because now I understand how this part of Linux works better!

So even getting to understand something that seems relatively basic like "when does a computer start swapping?" can take a while! There's a lot to know, and it's totally okay to not know it all right away.
A quick story on my Linux journey:
In 2003, when I was 15, my mom bought me a shiny new computer. I was really excited about Linux, so I installed a ton of different Linux distributions. (also, thanks to my mom!! I'm super lucky to have had a computer that I could bork repeatedly and the time & space to do tons of experiments)
Around 2009, in university, I was one of the sysadmins for a small lab of 7 Linux & Windows computers. The old sysadmin said "hey, want to help out?", gave me the root password, and we muddled our way through getting the computers to work for a bunch of math undergrads.
In 2013 I learned what a system call is and a bunch of basic things about operating systems! This was super awesome. (here's everything I learned at the Recurse Center
< And now I'm still continuing to learn.
In 2003, when I was 15, my mom bought me a shiny new computer. I was really excited about Linux, so I installed a ton of different Linux distributions. (also, thanks to my mom!! I'm super lucky to have had a computer that I could bork repeatedly and the time & space to do tons of experiments)
Around 2009, in university, I was one of the sysadmins for a small lab of 7 Linux & Windows computers. The old sysadmin said "hey, want to help out?", gave me the root password, and we muddled our way through getting the computers to work for a bunch of math undergrads.
In 2013 I learned what a system call is and a bunch of basic things about operating systems! This was super awesome. (here's everything I learned at the Recurse Center
< And now I'm still continuing to learn.

The next wizard skill I'm going to talk about is asking great questions!
A (great) situation I end up in a lot is where I have a coworker who knows something that I want to know, and they want to help me, and I just need to figure out the right questions to ask to get the answers I want!
Asking good questions is really important because people in general cannot just magically guess what I want them to tell me.
Asking good questions is really important because people in general cannot just magically guess what I want them to tell me.
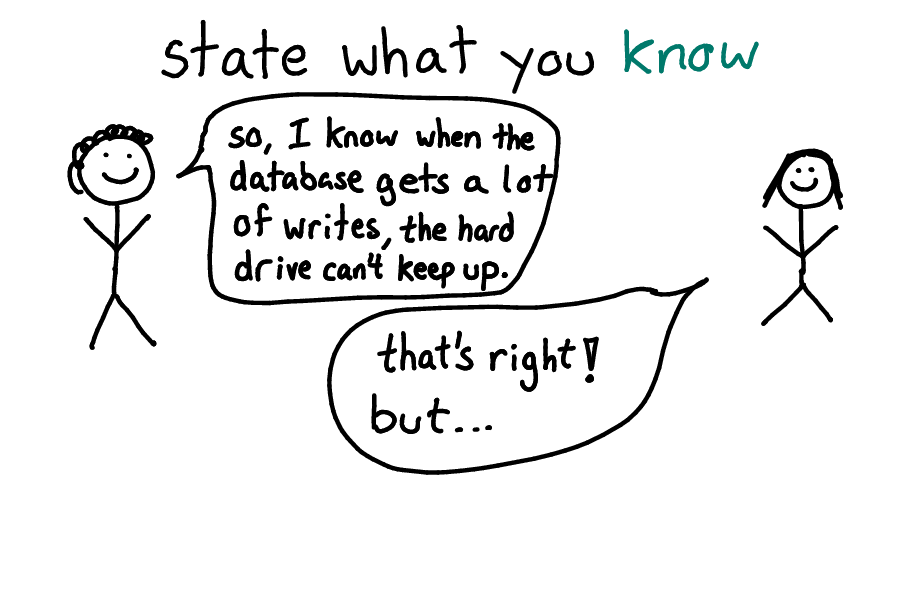
One of my favorite tricks is to state what I know, as a way to frame my question.

Stating what I know is awesome because it helps me organize my thoughts, reveals misunderstands (me: "I know X", them: "that not quite right!"), and helps me avoid answers that are too basic (yes yes yes i know that!) and too advanced (NO PLEASE BACK UP 30 STEPS FIRST).

When asking a question, it's pretty natural to want to ask the most experienced person around your question. They will probably know the answer, which is good! But I don't think it's the best strategy.
Instead, I instead try to remember to ask a less experienced person, who I think will still know the answer.
Instead, I instead try to remember to ask a less experienced person, who I think will still know the answer.

This is awesome because it reduces the load on the more-experienced person. But there's more reasons this is great! I'm not the most experienced member of my team. I love it when people ask me questions because -- if I don't know the answer to their questions, then I can find out, and I can grow my own knowledge.
So not asking the most experienced person is actually a cool way to show trust in less experienced team members, reduce the bus factor, and spread knowledge around.
So not asking the most experienced person is actually a cool way to show trust in less experienced team members, reduce the bus factor, and spread knowledge around.

Doing research is great! It lets me ask more complicated and interesting questions!
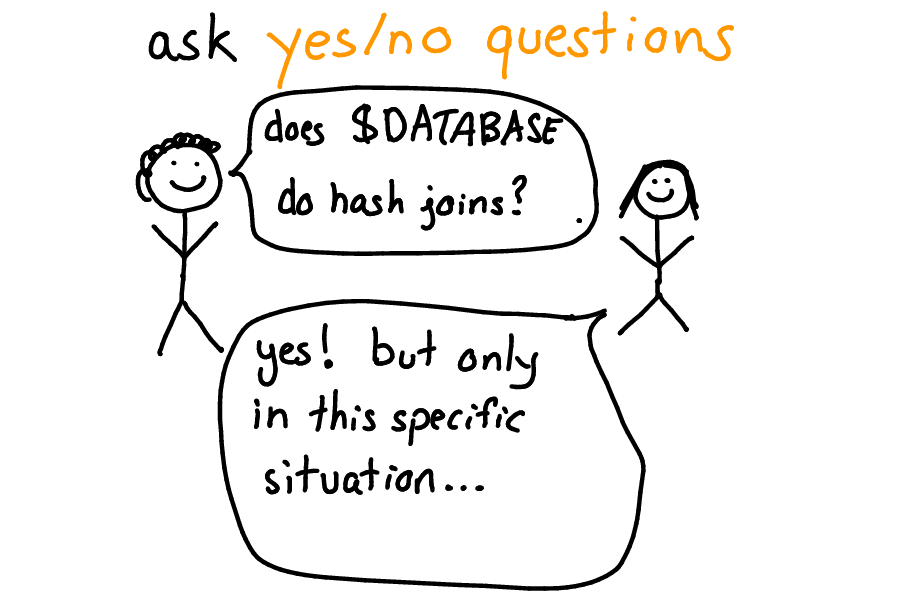
I really like to ask questions that are relatively easy to answer. yes/no questions are a really good way to accomplish this! And often an interesting yes/no question can lead to a great discussion.
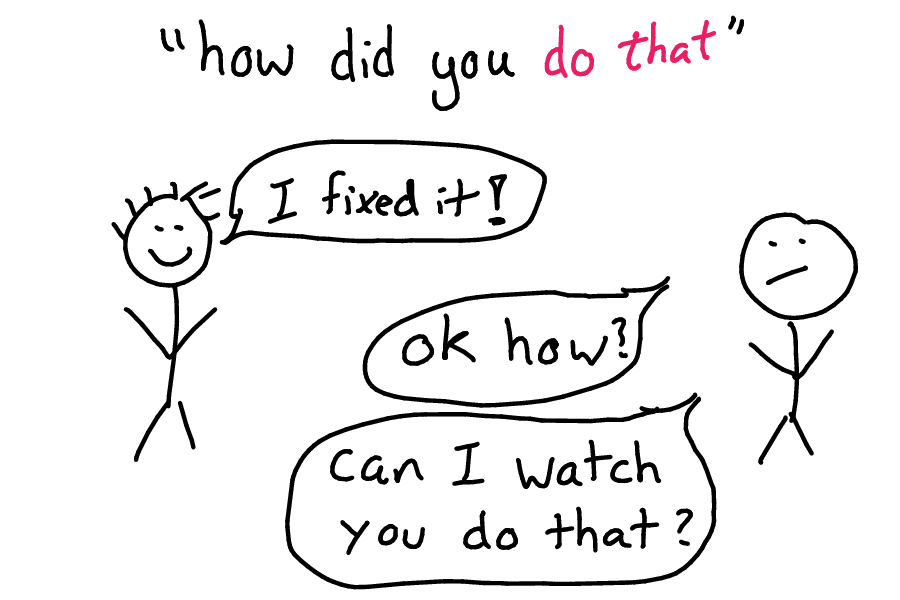
When debugging or fixing things, often you can end up in a situation where someone who's super experienced knows how to Do A Thing, and other people on the team don't know how.
And often they have trouble remembering all the details to document them! So I like to (right after someone did something) to ask them to explain exactly what they did, or to ask if I can watch while they do it.
And often they have trouble remembering all the details to document them! So I like to (right after someone did something) to ask them to explain exactly what they did, or to ask if I can watch while they do it.

The last thing I have to say about asking about questions, especially to senior engineers / managers / leaders is -- please ask questions in public. I find that it's much easier for senior people to admit that they don't know something (because everybody knows you're competent already!), and doing that really creates space for everyone to ask questions.

Okay, let's talk about reading code!

Sometimes error messages are not particularly helpful. If you go read the code around where the error message got printed, sometimes you can get a better clue about what's going on!

What's more exciting to me, though, is to read the code when software is poorly documented (which happens all the time, especially when it's changing frequently or isn't used by very many people)

I want to emphasize that reading code isn't just for small projects that you're familiar with, though.
In my first job, I was writing plugins to make websites with Drupal, a PHP content management system. Once I remember I had a really specific question about how some Drupal thing worked. It wasn't documented, and there were no results on Google when I looked.
I asked my boss at the time if he knew and he told me "julia, you just have to go read the code and find out how it works!". I was a bit unsure about how to approach it ("there's so much code") but he pointed me to the relevant part of the Drupal codebase, and, sure enough, I could see the answer to my question there!
Since then I've looked at the code for a bunch of large open source questions to answer questions (nginx! linux!) and even if I'm not a super good C programmer, sometimes I can figure out the answer to my question.
In my first job, I was writing plugins to make websites with Drupal, a PHP content management system. Once I remember I had a really specific question about how some Drupal thing worked. It wasn't documented, and there were no results on Google when I looked.
I asked my boss at the time if he knew and he told me "julia, you just have to go read the code and find out how it works!". I was a bit unsure about how to approach it ("there's so much code") but he pointed me to the relevant part of the Drupal codebase, and, sure enough, I could see the answer to my question there!
Since then I've looked at the code for a bunch of large open source questions to answer questions (nginx! linux!) and even if I'm not a super good C programmer, sometimes I can figure out the answer to my question.

Now we're going to talk about one of my favorite things! Debugging!
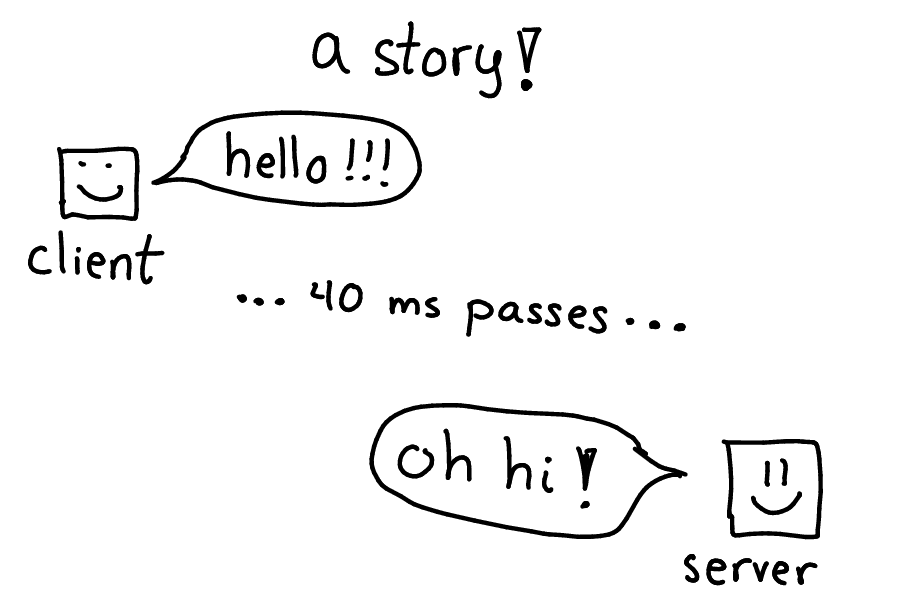
Let's tell a story! One day we had a client that was making a HTTP request, and it wasn't getting a response for 40 milliseconds. That's a long time!
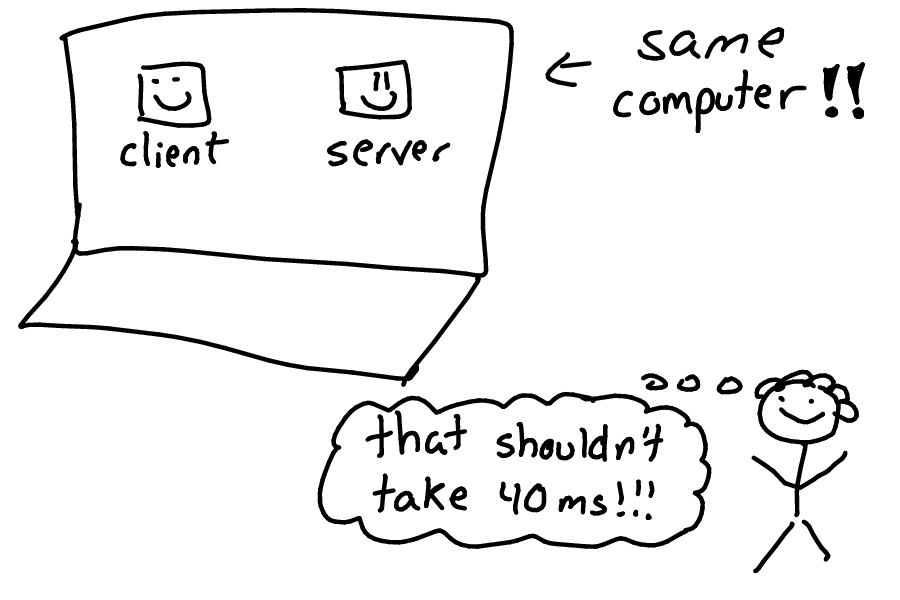
Why is that a long time? The client and the server were on the same computer. And I expected the server to be fast, so there was no reason for a 40ms delay.

As an aside, 40ms synchronously is 25 requests per second, which is really not a lot. It's easy to see how this kind of delay could become a problem quickly.
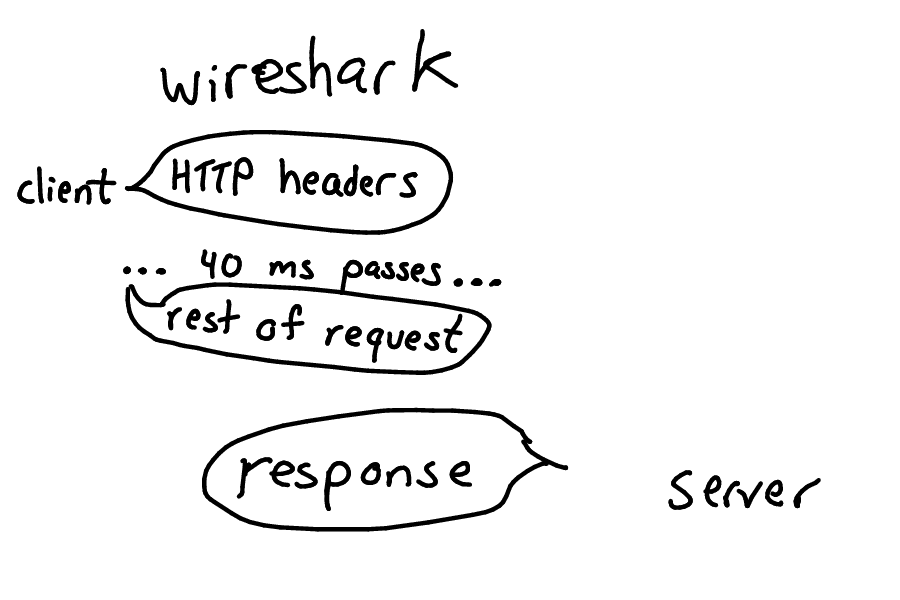
I captured some packets with Wireshark to figure out who I should be blaming -- the client or the server!
We found out that the client would send the HTTP headers, wait 40ms, and then send the rest of the request. So the server wasn't the problem at all! But why was the client doing this? It's written in Ruby, and initially I maybe thought we should just blame Ruby, but that wasn't a really good reason (40ms is a very long time, even in Ruby).
We found out that the client would send the HTTP headers, wait 40ms, and then send the rest of the request. So the server wasn't the problem at all! But why was the client doing this? It's written in Ruby, and initially I maybe thought we should just blame Ruby, but that wasn't a really good reason (40ms is a very long time, even in Ruby).
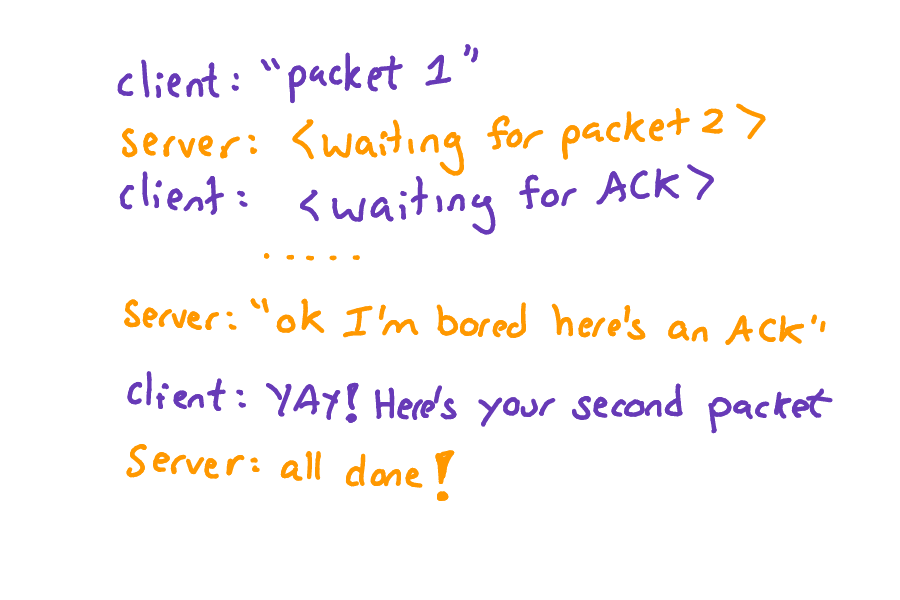
It turned out what was happening was a bad interaction between two TCP optimizations -- delayed ACKs, and Nagle's algorithm. When the client sent the first packet, the server would wait to send an ACK (because of the delayed ACKs algorithm), and the client was waiting for that ACK (because of Nagle's algorithm).
So they were stuck in this kind of passive-aggressive-waiting situation.
I wrote a blog post about this called Why you should understand (a little) about TCP if you want to know more.
So they were stuck in this kind of passive-aggressive-waiting situation.
I wrote a blog post about this called Why you should understand (a little) about TCP if you want to know more.

When we set the TCP_NODELAY socket option, it stopped the client from waiting, and then everything got fast!

A while ago I realized I felt like I'd gotten a lot better at debugging since my first job, and I came up with some reasons I think it got easier!

Sometimes when I hit a bug, especially a nondeterministic and difficult to reproduce bug, it’s tempting to think “oh you know, things just happen, who knows”. But everything on a computer does in fact happen for a logical reason (however much the computer may try to convince you otherwise). Reminding myself of that helps me fix bugs. Also known as “OK JULIA IT IS NOT FAIRIES WHAT ACTUAL REASON COULD BE CAUSING THIS?”

Next up, confidence!

A while ago I dealt with a performance problem in a Hadoop job at work that took me 2 weeks to fix (see a millisecond isn’t fast). If I hadn’t been able to fix it, I would have felt pretty bad and like it was a waste of 2 weeks.
But we were processing a relatively small number of records, and it was taking 15 hours to do it, and it was NOT REASONABLE and I knew that the job was too slow. And I figured it out, and now it’s faster and everyone is happy.
But we were processing a relatively small number of records, and it was taking 15 hours to do it, and it was NOT REASONABLE and I knew that the job was too slow. And I figured it out, and now it’s faster and everyone is happy.

From that, I learned that floating point exponentiation is slow, and that 1000 records/second isn't really a lot.

The job was processing 1000 records/second. I found this hard to think about at the time though -- was that a lot? not a lot? How was I supposed to know?
So I decided I wanted to take some time to train my intuitions about how fast different computer operations should be.
So I decided I wanted to take some time to train my intuitions about how fast different computer operations should be.

I made this game called computers are fast with my partner Kamal. You can go play it online, and we're going to play it now a little bit!

Suppose you have an indexed database table, with 10 million rows in it. How long does it take to select a row from that table? How many times per second can you do that?
The goal isn't to know exactly, but I think it's useful to be right up to an order of magnitude. So can you do it 100 times in a second? 10,000? 10 million times?
The goal isn't to know exactly, but I think it's useful to be right up to an order of magnitude. So can you do it 100 times in a second? 10,000? 10 million times?

It turns out the answer on my laptop is 55,000 times! (or, it takes about 20 microseconds, in Python)

It's also been incredibly helpful for me to have better tools for answering questions about your programs!
When I started out, I didn't have very good tools! But now I know about all kinds of profilers! I know about strace, and tcpdump, and way more tools for figuring out what's going on. It makes a huge difference.
When I started out, I didn't have very good tools! But now I know about all kinds of profilers! I know about strace, and tcpdump, and way more tools for figuring out what's going on. It makes a huge difference.

I wrote a whole zine about debugging tools that have helped me answer questions. You can read it here: Linux debugging tools you'll love
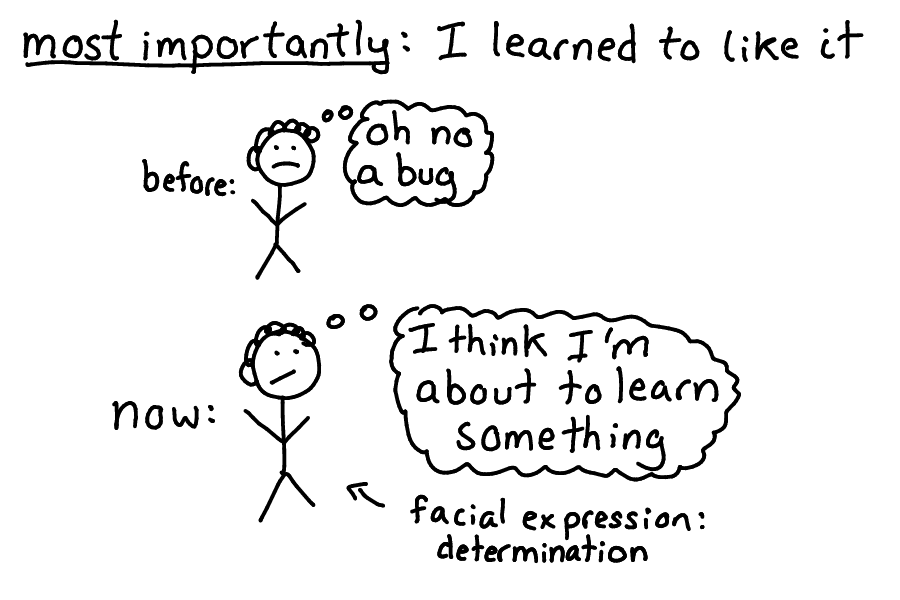
But maybe the most important thing is that I learned to like debugging! I used to get grumpy when I ran into bugs. I felt like they were just getting in my way!
But these days, when I run into a mysterious bug, I think it's kind of fun! I get to improve my understanding of the systems I work with, which is awesome!
But these days, when I run into a mysterious bug, I think it's kind of fun! I get to improve my understanding of the systems I work with, which is awesome!

Now we're going to zoom out a bit from talking about networking and microseconds, and talk about how to design engineering projects. This is something that's really helped me a lot!

There are a lot of words for design document, but they're basically all the same idea -- you write down words about what work you're going to do before doing the work.

When I started at Stripe I thought writing stuff down was kind of dumb. Why couldn't I just start working on the project?
But since then, I've learned to find them really useful! (learning to like design documents)
But since then, I've learned to find them really useful! (learning to like design documents)
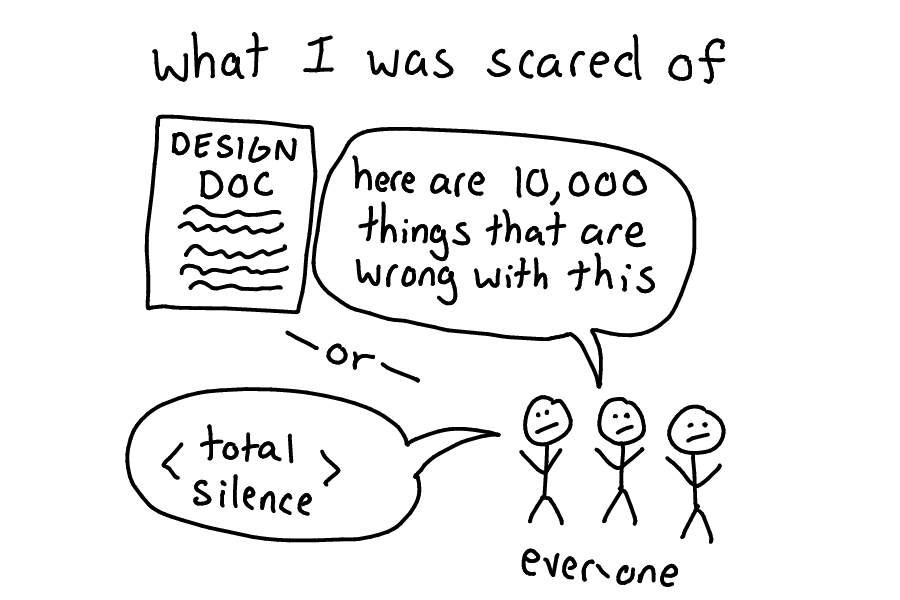
I was worried that if I wrote a document, I'd either get WAY TOO MUCH feedback, or total silence.
One thing I learned is that it's helpful at first to just share a design I'm working with a few people. Like I'll show it to a couple of other people on my team, see what they think, and then make changes! It's not always necessary to ask every single person who might have an opinion what they think.
One thing I learned is that it's helpful at first to just share a design I'm working with a few people. Like I'll show it to a couple of other people on my team, see what they think, and then make changes! It's not always necessary to ask every single person who might have an opinion what they think.
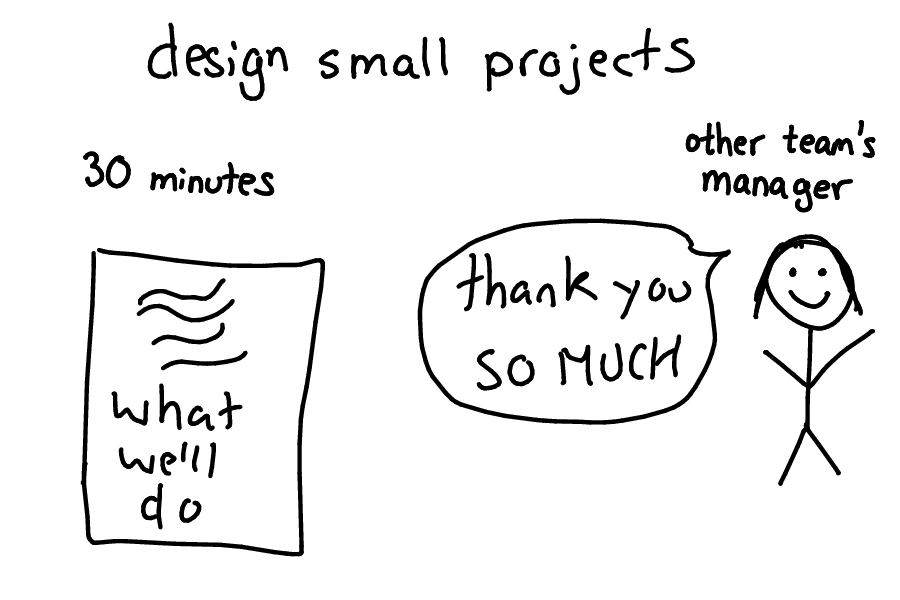
I also learned to like designing small projects. Recently I worked on a tiny project that just took about a week. My team lead asked me if I could quickly write up what we were going to do.
It took me maybe 45 minutes to write up the plan (super fast!), I showed it to a manager on another team, he had a couple of things he asked me to do differently, and he was SO HAPPY I'd written down a plan so that he understood what was going on. Awesome!
The small project went super smoothly and I was really happly I wrote up a thing about it first.
It took me maybe 45 minutes to write up the plan (super fast!), I showed it to a manager on another team, he had a couple of things he asked me to do differently, and he was SO HAPPY I'd written down a plan so that he understood what was going on. Awesome!
The small project went super smoothly and I was really happly I wrote up a thing about it first.

How do you know what to write in a design document? I really like to start by writing an announcement email, as if we just finished the project.
This is great because it forces me to articulate why the project is important (why did we spend all that time on it), how it's going to impact other teams and what other people in the organization need to know about, and how we know that we actually met our goals for the project
The last thing is really important -- more often than I'd like to admit, I get to the end of a project and realize I'm not quite sure how we can tell whether the project is actually going to improve things or not. Planning that out at the beginning helps make sure that we put in the right metrics!
This is great because it forces me to articulate why the project is important (why did we spend all that time on it), how it's going to impact other teams and what other people in the organization need to know about, and how we know that we actually met our goals for the project
The last thing is really important -- more often than I'd like to admit, I get to the end of a project and realize I'm not quite sure how we can tell whether the project is actually going to improve things or not. Planning that out at the beginning helps make sure that we put in the right metrics!

It's also useful to talk about risks! I actually haven't done this yet, but a cool idea I heard recently for figuring out risks was to do a "premortem" for your project. This is kind of the opposite of an announcement email -- instead, you imagine that the project failed 6 months down the line, and you're making sure you understand why it failed.

When I started writing designs, I used to worry a lot that my design would be wrong because things were going to change. It turns out that this is totally true -- designs rarely survive contact with the real world. Priorities change, you run into technical challenges you didn't expect, all kinds of things can go wrong.
But this doesn't mean it's not worth designing at all! I like writing down my assumptions explicitly because when things do change, I can go back and see what assumptions we had are no longer true, and make sure that we update everything we need to update. Having a record of changes is useful!
But this doesn't mean it's not worth designing at all! I like writing down my assumptions explicitly because when things do change, I can go back and see what assumptions we had are no longer true, and make sure that we update everything we need to update. Having a record of changes is useful!

We've arrived at the last wizard skill!

Sometimes I'm working on something kind of boring, and I wonder like.. why am I doing this?
I usually find it possible to stay motivated if I can remember "ok, I'm spending hours working on configuring nginx, and this is boring, but it's in service of this really cool goal!"
But if I *don't* remember the goal (or what I'm working on actually doesn't make sense), it sucks.
I usually find it possible to stay motivated if I can remember "ok, I'm spending hours working on configuring nginx, and this is boring, but it's in service of this really cool goal!"
But if I *don't* remember the goal (or what I'm working on actually doesn't make sense), it sucks.

The solution I'm working on to this right now is to approach project planning with the same kind of excitement and curiosity you might bring to a gnarly bug!
I'm trying to get better at saying "okay!!! this project! it has some slow and difficult pieces, so why is it so important? why are we going to feel awesome when it's done? which parts are the most important?"
I'm trying to get better at saying "okay!!! this project! it has some slow and difficult pieces, so why is it so important? why are we going to feel awesome when it's done? which parts are the most important?"

I have a lot of autonomy in about what I get to work on, so when someone asks me to do something, I like to make sure I understand why it's important. Usually if I don't understand, the right thing to do is to just find out why it's important (usually it actually is!).
But sometimes the task I'm being given is only maybe 80% thought through, and when I go to understand the exact reason for doing it, it turns out that we don't need to do it at all! (or maybe we should actually be doing something completely different!)
But sometimes the task I'm being given is only maybe 80% thought through, and when I go to understand the exact reason for doing it, it turns out that we don't need to do it at all! (or maybe we should actually be doing something completely different!)
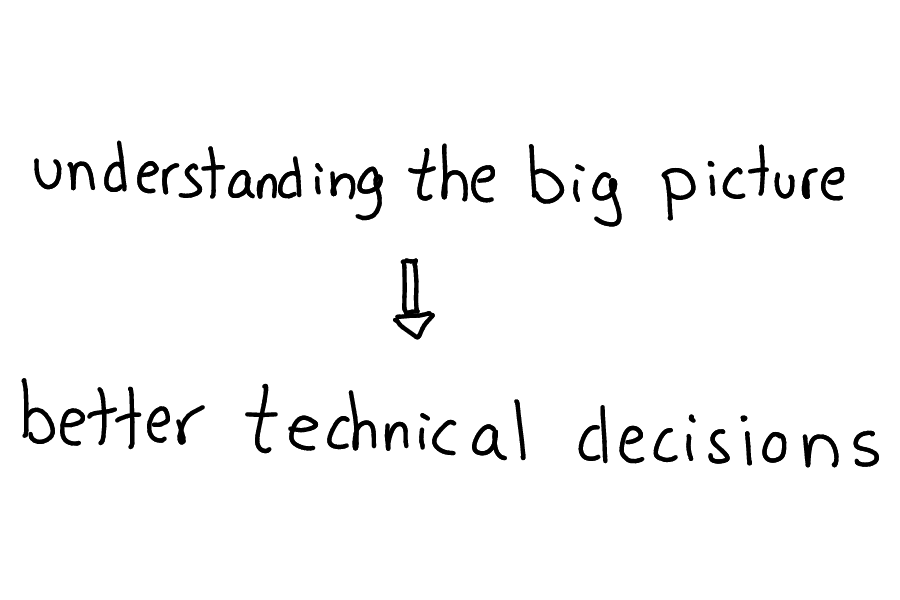
And understanding the big picture helps me make better technical decisions!

Like a lot of people, I think a lot about the impact my work has and what I'm really doing here. Kelsey Hightower had a really amazing series of tweets today. here are a couple of quotes.
> I’ve yet to find the perfect job or thing to work on, but I have found a way to live a more meaningful life in tech.
> I now put people first. Regardless of the technology involved I gravitate towards helping people.
> People provide a much better feedback loop than computers or the abstract idea of a business.
> Everything I work on has a specific person or group of people in mind; this is what gives my work meaning; solving problems is not enough.
> I’ve yet to find the perfect job or thing to work on, but I have found a way to live a more meaningful life in tech.
> I now put people first. Regardless of the technology involved I gravitate towards helping people.
> People provide a much better feedback loop than computers or the abstract idea of a business.
> Everything I work on has a specific person or group of people in mind; this is what gives my work meaning; solving problems is not enough.



during this conference, I hope you ask a ton of questions to understand what's going on with this "SRE" thing better. There are so many amazing people to learn from!


I handed out fun networking zines at the end of this talk. If you want to read the zine, it's here: Networking! ACK!