Hello! A couple of days I wrote about tiny personal programs, and I mentioned that it can be fun to use “secret” undocumented APIs where you need to copy your cookies out of the browser to get access to them.
A couple of people asked how to do this, so I wanted to explain how because it’s pretty straightforward. We’ll also talk a tiny bit about what can go wrong, ethical issues, and how this applies to your undocumented APIs.
As an example, let’s use Google Hangouts. I’m picking this not because it’s the most useful example (I think there’s an official API which would be much more practical to use), but because many sites where this is actually useful are smaller sites that are more vulnerable to abuse. So we’re just going to use Google Hangouts because I’m 100% sure that the Google Hangouts backend is designed to be resilient to this kind of poking around.
Let’s get started!
step 1: look in developer tools for a promising JSON response
I start out by going to https://hangouts.google.com, opening the network tab in Firefox developer tools and looking for JSON responses. You can use Chrome developer tools too.
Here’s what that looks like
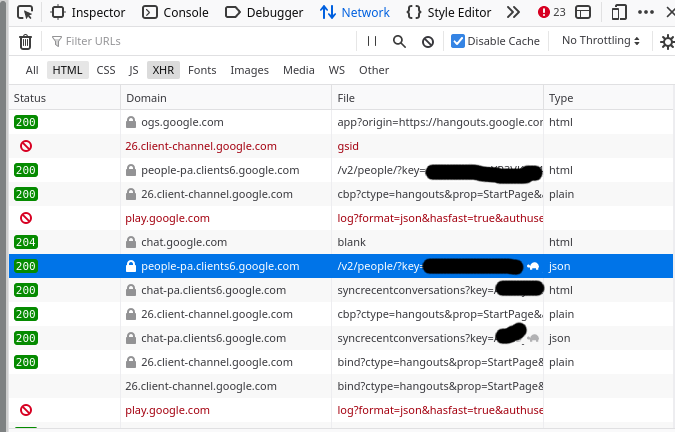
The request is a good candidate if it says “json” in the “Type” column”
I had to look around for a while until I found something interesting, but eventually I found a “people” endpoint that seems to return information about my contacts. Sounds fun, let’s take a look at that.
step 2: copy as cURL
Next, I right click on the request I’m interested in, and click “Copy” -> “Copy as cURL”.
Then I paste the curl command in my terminal and run it. Here’s what happens.
$ curl 'https://people-pa.clients6.google.com/v2/people/?key=REDACTED' -X POST ........ (a bunch of headers removed)
Warning: Binary output can mess up your terminal. Use "--output -" to tell
Warning: curl to output it to your terminal anyway, or consider "--output
Warning: <FILE>" to save to a file.
You might be thinking – that’s weird, what’s this “binary output can mess up
your terminal” error? That’s because by default, browsers send an
Accept-Encoding: gzip, deflate header to the server, to get compressed
output.
We could decompress it by piping the output to gunzip, but I find it simpler
to just not send that header. So let’s remove some irrelevant headers.
step 3: remove irrelevant headers
Here’s the full curl command line that I got from the browser. There’s a lot here!
I start out by splitting up the request with backslashes (\) so that each header is on a different line to make it easier to work with:
curl 'https://people-pa.clients6.google.com/v2/people/?key=REDACTED' \
-X POST \
-H 'User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:96.0) Gecko/20100101 Firefox/96.0' \
-H 'Accept: */*' \
-H 'Accept-Language: en' \
-H 'Accept-Encoding: gzip, deflate' \
-H 'X-HTTP-Method-Override: GET' \
-H 'Authorization: SAPISIDHASH REDACTED' \
-H 'Cookie: REDACTED'
-H 'Content-Type: application/x-www-form-urlencoded' \
-H 'X-Goog-AuthUser: 0' \
-H 'Origin: https://hangouts.google.com' \
-H 'Connection: keep-alive' \
-H 'Referer: https://hangouts.google.com/' \
-H 'Sec-Fetch-Dest: empty' \
-H 'Sec-Fetch-Mode: cors' \
-H 'Sec-Fetch-Site: same-site' \
-H 'Sec-GPC: 1' \
-H 'DNT: 1' \
-H 'Pragma: no-cache' \
-H 'Cache-Control: no-cache' \
-H 'TE: trailers' \
--data-raw 'personId=101777723309&personId=1175339043204&personId=1115266537043&personId=116731406166&extensionSet.extensionNames=HANGOUTS_ADDITIONAL_DATA&extensionSet.extensionNames=HANGOUTS_OFF_NETWORK_GAIA_GET&extensionSet.extensionNames=HANGOUTS_PHONE_DATA&includedProfileStates=ADMIN_BLOCKED&includedProfileStates=DELETED&includedProfileStates=PRIVATE_PROFILE&mergedPersonSourceOptions.includeAffinity=CHAT_AUTOCOMPLETE&coreIdParams.useRealtimeNotificationExpandedAcls=true&requestMask.includeField.paths=person.email&requestMask.includeField.paths=person.gender&requestMask.includeField.paths=person.in_app_reachability&requestMask.includeField.paths=person.metadata&requestMask.includeField.paths=person.name&requestMask.includeField.paths=person.phone&requestMask.includeField.paths=person.photo&requestMask.includeField.paths=person.read_only_profile_info&requestMask.includeField.paths=person.organization&requestMask.includeField.paths=person.location&requestMask.includeField.paths=person.cover_photo&requestMask.includeContainer=PROFILE&requestMask.includeContainer=DOMAIN_PROFILE&requestMask.includeContainer=CONTACT&key=REDACTED'
This can seem like an overwhelming amount of stuff at first, but you don’t need to think about what any of it means at this stage. You just need to delete irrelevant lines.
I usually just figure out which headers I can delete with trial and error – I
keep removing headers until the request starts failing. In general you probably
don’t need Accept*, Referer, Sec-*, DNT, User-Agent, and caching
headers though.
In this example, I was able to cut the request down to this:
curl 'https://people-pa.clients6.google.com/v2/people/?key=REDACTED' \
-X POST \
-H 'Authorization: SAPISIDHASH REDACTED' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-H 'Origin: https://hangouts.google.com' \
-H 'Cookie: REDACTED'\
--data-raw 'personId=101777723309&personId=1175339043204&personId=1115266537043&personId=116731406166&extensionSet.extensionNames=HANGOUTS_ADDITIONAL_DATA&extensionSet.extensionNames=HANGOUTS_OFF_NETWORK_GAIA_GET&extensionSet.extensionNames=HANGOUTS_PHONE_DATA&includedProfileStates=ADMIN_BLOCKED&includedProfileStates=DELETED&includedProfileStates=PRIVATE_PROFILE&mergedPersonSourceOptions.includeAffinity=CHAT_AUTOCOMPLETE&coreIdParams.useRealtimeNotificationExpandedAcls=true&requestMask.includeField.paths=person.email&requestMask.includeField.paths=person.gender&requestMask.includeField.paths=person.in_app_reachability&requestMask.includeField.paths=person.metadata&requestMask.includeField.paths=person.name&requestMask.includeField.paths=person.phone&requestMask.includeField.paths=person.photo&requestMask.includeField.paths=person.read_only_profile_info&requestMask.includeField.paths=person.organization&requestMask.includeField.paths=person.location&requestMask.includeField.paths=person.cover_photo&requestMask.includeContainer=PROFILE&requestMask.includeContainer=DOMAIN_PROFILE&requestMask.includeContainer=CONTACT&key=REDACTED'
So I just need 4 headers: Authorization, Content-Type, Origin, and Cookie. That’s a lot more manageable.
step 4: translate it into Python
Now that we know what headers we need, we can translate our curl command into a Python program!
This part is also a pretty mechanical process, the goal is just to send exactly the same data with Python as we were with curl.
Here’s what that looks like. This is exactly the same as the previous curl
command, but using Python’s requests. I also broke up the very long request body
string into an array of tuples to make it easier to work with
programmatically.
import requests
import urllib
data = [
('personId','101777723'), # I redacted these IDs a bit too
('personId','117533904'),
('personId','111526653'),
('personId','116731406'),
('extensionSet.extensionNames','HANGOUTS_ADDITIONAL_DATA'),
('extensionSet.extensionNames','HANGOUTS_OFF_NETWORK_GAIA_GET'),
('extensionSet.extensionNames','HANGOUTS_PHONE_DATA'),
('includedProfileStates','ADMIN_BLOCKED'),
('includedProfileStates','DELETED'),
('includedProfileStates','PRIVATE_PROFILE'),
('mergedPersonSourceOptions.includeAffinity','CHAT_AUTOCOMPLETE'),
('coreIdParams.useRealtimeNotificationExpandedAcls','true'),
('requestMask.includeField.paths','person.email'),
('requestMask.includeField.paths','person.gender'),
('requestMask.includeField.paths','person.in_app_reachability'),
('requestMask.includeField.paths','person.metadata'),
('requestMask.includeField.paths','person.name'),
('requestMask.includeField.paths','person.phone'),
('requestMask.includeField.paths','person.photo'),
('requestMask.includeField.paths','person.read_only_profile_info'),
('requestMask.includeField.paths','person.organization'),
('requestMask.includeField.paths','person.location'),
('requestMask.includeField.paths','person.cover_photo'),
('requestMask.includeContainer','PROFILE'),
('requestMask.includeContainer','DOMAIN_PROFILE'),
('requestMask.includeContainer','CONTACT'),
('key','REDACTED')
]
response = requests.post('https://people-pa.clients6.google.com/v2/people/?key=REDACTED',
headers={
'X-HTTP-Method-Override': 'GET',
'Authorization': 'SAPISIDHASH REDACTED',
'Content-Type': 'application/x-www-form-urlencoded',
'Origin': 'https://hangouts.google.com',
'Cookie': 'REDACTED',
},
data=urllib.parse.urlencode(data),
)
print(response.text)
I ran this program and it works – it prints out a bunch of JSON! Hooray!
You’ll notice that I replaced a bunch of things with REDACTED, that’s because
if I included those values you could access the Google Hangouts API for my
account which would be no good.
and we’re done!
Now I can modify the Python program to do whatever I want, like passing different parameters or parsing the output.
I’m not going to do anything interesting with it because I’m not actually interested in using this API at all, I just wanted to show what the process looks like.
But we get back a bunch of JSON that you could definitely do something with.
curlconverter looks great
Someone commented that you can translate curl to Python (and a bunch of other languages!) automatically with https://curlconverter.com/ which looks amazing – I’ve always done it manually. I tried it out on this example and it seems to work great.
figuring out how the API works is nontrivial
I don’t want to undersell how difficult it can be to figure out how an unknown API works – it’s not obvious! I have no idea what a lot of the parameters to this Google Hangouts API do!
But a lot of the time there are some parameters that seem pretty straightforward,
like requestMask.includeField.paths=person.email probably means “include each
person’s email address”. So I try to focus on the parameters I do understand
more than the ones I don’t understand.
this always works (in theory)
Some of you might be wondering – can you always do this?
The answer is sort of yes – browsers aren’t magic! All the information browsers send to your backend is just HTTP requests. So if I copy all of the HTTP headers that my browser is sending, I think there’s literally no way for the backend to tell that the request isn’t sent by my browser and is actually being sent by a random Python program.
Of course, we removed a bunch of the headers the browser sent so theoretically the backend could tell, but usually they won’t check.
There are some caveats though – for example a lot of Google services have backends that communicate with the frontend in a totally inscrutable (to me) way, so even though in theory you could mimic what they’re doing, in practice it might be almost impossible. And bigger APIs that encounter more abuse will have more protections.
Now that we’ve seen how to use undocumented APIs like this, let’s talk about some things that can go wrong.
problem 1: expiring session cookies
One big problem here is that I’m using my Google session cookie for authentication, so this script will stop working whenever my browser session expires.
That means that this approach wouldn’t work for a long running program (I’d want to use a real API), but if I just need to quickly grab a little bit of data as a 1-time thing, it can work great!
problem 2: abuse
If I’m using a small website, there’s a chance that my little Python script could take down their service because it’s doing way more requests than they’re able to handle. So when I’m doing this I try to be respectful and not make too many requests too quickly.
This is especially important because a lot of sites which don’t have official APIs are smaller sites with less resources.
In this example obviously this isn’t a problem – I think I made 20 requests total to the Google Hangouts backend while writing this blog post, which they can definitely handle.
Also if you’re using your account credentials to access the API in a excessive way and you cause problems, you might (very reasonably) get your account suspended.
I also stick to downloading data that’s either mine or that’s intended to be publicly accessible – I’m not searching for vulnerabilities.
remember that anyone can use your undocumented APIs
I think the most important thing to know about this isn’t actually how to use other people’s undocumented APIs. It’s fun to do, but it has a lot of limitations and I don’t actually do it that often.
It’s much more important to understand that anyone can do this to your backend API! Everyone has developer tools and the network tab, and it’s pretty easy to see which parameters you’re passing to the backend and to change them.
So if anyone can just change some parameters to get another user’s information, that’s no good. I think most developers building publicly available APIs know this, but I’m mentioning it because everyone needs to learn it for the first time at some point :)