Hi friends! I was helping decide between some Ruby HTTP client libraries at work, and I learned a couple of things that surprised me (and some decisions I didn’t agree with).
I ended up doing a tiny amount of open source archaeology, with interesting results! Let’s learn some things!
Ruby HTTP libraries: a taxonomy
A HTTP library is conceptually a really simple thing – all HTTP is, for the most part, is you send some text to a server (GET /awesomepage.html), and they send you some other text back (omg cats). But it turns out that HTTP has a lot of features, so we have libraries that help us put together those requests and parse the responses for us.
There’s this fantastic slideshow comparing HTTP libraries. And it has this great slide:
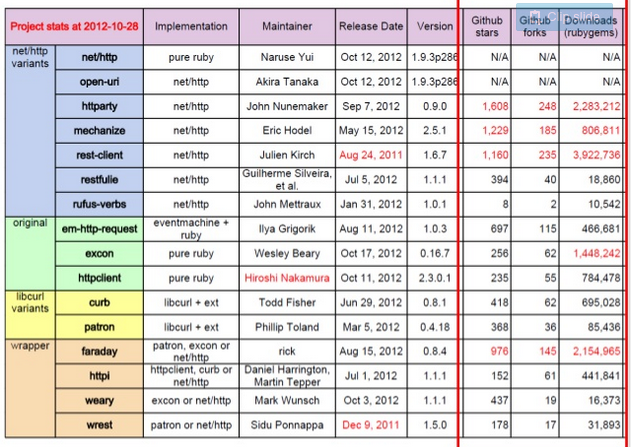
This slide tells us that there are basically only 4 HTTP libraries in Ruby:
- Net::HTTP (built into Ruby)
- Excon
- httpclient
- variants on bindings for libcurl (a C HTTP library, that
curluses)
That’s it. Every other library builds on top of those libraries. We can classify these even further! Net::HTTP, Excon, and httpclient all use Ruby’s built-in socket library to make TCP connections. So the real taxonomy is
* Socket interface (operating system)
* Ruby socket library
* Excon
* Net::HTTP
* httpclient
* libcurl
* Ruby bindings for libcurl (curb)
I find taxonomies like this super helpful when trying to understand a landscape of possibilities. Instead of having 15 or 20 libraries to think about, now there are just 4!
I’m only going to say things about 2 libraries: Excon and Net::HTTP
A surprise in Net::HTTP
There’s a post on the front page of HN today about how nginx proxies will retry HTTP requests. This is undesirable and scary because – when you make a request, often you expect it to happen just once! What if your GET request means “execute this trade”? Then it shouldn’t just get randomly retried – you want control over that!
Similarly, Net::HTTP will retry your GET, HEAD, PUT, DELETE, OPTIONS, and TRACE requests. As far as I can tell, you cannot turn this off. Here’s the code that does it.
the code snippet:
if count == 0 && IDEMPOTENT_METHODS_.include?(req.method)
count += 1
@socket.close if @socket and not @socket.closed?
D "Conn close because of error #{exception}, and retry"
retry
end
I was really surprised and kind of taken aback to learn this. I wanted to find out why it was this say, so I found the issue in the Ruby bug tracker that introduced this behavior!. It turns out that this retry feature was added to Ruby in 2012! And it was added because the RFC for HTTP/1.1 recommends that HTTP clients act this way.
Client software SHOULD reopen the transport connection and retransmit the aborted sequence of requests without user interaction so long as the request sequence is idempotent (see section 9.1.2).
Huh. This is (as you would see if I linked to a comment thread on the nginx blog post) a controversial choice – it makes a lot of sense for a web browser to retry, and perhaps less sense for a library you’re calling from your code to automatically retry, without the ability configure it.
A surprise in Excon
A while ago, I wrote Why you should understand (a little) about TCP, where I had Mysterious Slow HTTP Requests that were slow for no reason. This was because of Excon! When you make a HTTP request with a body (like a POST request) with Excon, it does the equivalent of
socket.write(headers)
socket.write(body)
This ends up creating 2 TCP packets for the request, and can cause your packets to be delayed (as I talk about in that TCP post). This is no good!
I looked into the history of this in Excon. There’s an Github issue referencing Nagle’s algorithm and this exact performance problem from 2013, and it appears to have been fixed, and then reverted to the old behavior again in this issue, because they had problems doing string concatenation. So it seems like the library’s authors understood the choice they were making, but just didn’t have time to address it.
Update: this is now fixed in Excon, as of release v0.48.0 on March 7, 2016. (pull request). Yay!
How do we find surprises? (or: reviewing a library)
The scariest thing about introducing dependencies to me is – how do I know if it will surprise me unpleasantly a year from now, in production?
I haven’t done this very much, and I’d like to get better at it. I have a couple of thoughts to start.
First, Net::HTTP is maybe 2000 lines of code, not including comments. It has ~1000 lines of comments. The code’s right here.. A lot of it is wrapper methods! At work, I’d consider a 2000-line pull request somewhat arduous to review, but perhaps not totally outside the bounds of reasonableness! I can read 2000 lines of code, mostly!
So I tried. I found that Net::HTTP always sets TCP_NODELAY and that it’s careful to use a monotonic clock when checking for timeouts. The first one is surprising to me! I would expect that to be configurable too. I did not try too hard to read Excon’s code because at this point it was way after midnight.
The second idea I had for understanding some code is – try to think of all the situations I might want to run the code in, and strace all those situations! Then I could see if it ran the system calls I expect.
I am still Very Inexperienced at reviewing dependencies like this. Something which isn’t like 2000 lines of code would be way harder to try to review! But it occurs to me that security people audit code regularly, and so reading libraries to understand what they do and if they’re safe to use is perhaps not totally abnormal.
open source!
It turns out that open source projects are just like all software projects – they do unexpected stuff, and then when I go find out why a person decided to do that I’m usually like “oh, I see why you made that decision!” Even if I don’t agree.
When I run into code that does stuff I don’t agree with, I’m reminded of this great paragraph from On Being a Senior Engineer –
Critique code instead of people – be kind to the coder, not to the code. As much as possible, make all of your comments positive and oriented to improving the code. Relate comments to local standards, program specs, increased performance, etc.